
- Installation
- Documentation
- Getting Started
- Connect
- Data Import and Export
- Overview
- Data Sources
- CSV Files
- JSON Files
- Overview
- Creating JSON
- Loading JSON
- Writing JSON
- JSON Type
- JSON Functions
- Format Settings
- Installing and Loading
- SQL to / from JSON
- Caveats
- Multiple Files
- Parquet Files
- Partitioning
- Appender
- INSERT Statements
- Lakehouse Formats
- Client APIs
- Overview
- ADBC
- C
- Overview
- Startup
- Configuration
- Query
- Data Chunks
- Vectors
- Values
- Types
- Prepared Statements
- Appender
- Table Functions
- Replacement Scans
- API Reference
- C++
- CLI
- Overview
- Arguments
- Dot Commands
- Output Formats
- Editing
- Friendly CLI
- Safe Mode
- Autocomplete
- Syntax Highlighting
- Known Issues
- Go
- Java (JDBC)
- Node.js (Neo)
- ODBC
- Python
- Overview
- Data Ingestion
- Conversion between DuckDB and Python
- DB API
- Relational API
- Function API
- Types API
- Expression API
- Spark API
- API Reference
- Known Python Issues
- R
- Rust
- Wasm
- Tertiary Clients
- SQL
- Introduction
- Statements
- Overview
- ANALYZE
- ALTER TABLE
- ALTER VIEW
- ATTACH and DETACH
- CALL
- CHECKPOINT
- COMMENT ON
- COPY
- CREATE INDEX
- CREATE MACRO
- CREATE SCHEMA
- CREATE SECRET
- CREATE SEQUENCE
- CREATE TABLE
- CREATE VIEW
- CREATE TYPE
- DELETE
- DESCRIBE
- DROP
- EXPORT and IMPORT DATABASE
- INSERT
- LOAD / INSTALL
- MERGE INTO
- PIVOT
- Profiling
- SELECT
- SET / RESET
- SET VARIABLE
- SHOW and SHOW DATABASES
- SUMMARIZE
- Transaction Management
- UNPIVOT
- UPDATE
- USE
- VACUUM
- Query Syntax
- SELECT
- FROM and JOIN
- WHERE
- GROUP BY
- GROUPING SETS
- HAVING
- ORDER BY
- LIMIT and OFFSET
- SAMPLE
- Unnesting
- WITH
- WINDOW
- QUALIFY
- VALUES
- FILTER
- Set Operations
- Prepared Statements
- Data Types
- Overview
- Array
- Bitstring
- Blob
- Boolean
- Date
- Enum
- Geometry
- Interval
- List
- Literal Types
- Map
- NULL Values
- Numeric
- Struct
- Text
- Time
- Timestamp
- Time Zones
- Union
- Typecasting
- Variant
- Expressions
- Overview
- CASE Expression
- Casting
- Collations
- Comparisons
- IN Operator
- Logical Operators
- Star Expression
- Subqueries
- TRY
- Functions
- Overview
- Aggregate Functions
- Array Functions
- Bitstring Functions
- Blob Functions
- Date Format Functions
- Date Functions
- Date Part Functions
- Enum Functions
- Geometry Functions
- Interval Functions
- Lambda Functions
- List Functions
- Map Functions
- Nested Functions
- Numeric Functions
- Pattern Matching
- Regular Expressions
- Struct Functions
- Text Functions
- Time Functions
- Timestamp Functions
- Timestamp with Time Zone Functions
- Union Functions
- Utility Functions
- Window Functions
- Constraints
- Indexes
- Meta Queries
- DuckDB's SQL Dialect
- Overview
- Indexing
- Friendly SQL
- Keywords and Identifiers
- Order Preservation
- PostgreSQL Compatibility
- SQL Quirks
- PEG Parser
- Samples
- Configuration
- Extensions
- Overview
- Installing Extensions
- Advanced Installation Methods
- Distributing Extensions
- Versioning of Extensions
- Troubleshooting of Extensions
- Core Extensions
- Overview
- AutoComplete
- Avro
- AWS
- Azure
- Delta
- DuckLake
- Encodings
- Excel
- Full Text Search
- httpfs (HTTP and S3)
- Iceberg
- ICU
- inet
- jemalloc
- Lance
- MotherDuck
- MySQL
- ODBC
- Quack
- PostgreSQL
- Spatial
- SQLite
- TPC-DS
- TPC-H
- UI
- Unity Catalog
- Vortex
- VSS
- Quack Remote Protocol
- Guides
- Overview
- Data Viewers
- Database Integration
- File Formats
- Overview
- CSV Import
- CSV Export
- Directly Reading Files
- Directly Reading DuckDB Databases
- Excel Import
- Excel Export
- JSON Import
- JSON Export
- Parquet Import
- Parquet Export
- Querying Parquet Files
- File Access with the file: Protocol
- Meta Queries
- Describe Table
- EXPLAIN: Inspect Query Plans
- EXPLAIN ANALYZE: Profile Queries
- List Tables
- Summarize
- DuckDB Environment
- Network and Cloud Storage
- Overview
- HTTP Parquet Import
- S3 Parquet Import
- S3 Parquet Export
- S3 Iceberg Import
- S3 Express One
- GCS Import
- Cloudflare R2 Import
- DuckDB over HTTPS / S3
- Fastly Object Storage Import
- Tigris Import
- ODBC
- Performance
- Overview
- Environment
- Import
- Schema
- Indexing
- Join Operations
- File Formats
- How to Tune Workloads
- My Workload Is Slow
- Out-of-Memory Issues
- Benchmarks
- Working with Huge Databases
- Python
- Installation
- Executing SQL
- Jupyter Notebooks
- marimo Notebooks
- SQL on Pandas
- Import from Pandas
- Export to Pandas
- Import from Numpy
- Export to Numpy
- SQL on Arrow
- Import from Arrow
- Export to Arrow
- Relational API on Pandas
- Multiple Python Threads
- Integration with Ibis
- Integration with Polars
- Integration with PyTorch
- Using fsspec Filesystems
- SQL Editors
- SQL Features
- AsOf Join
- Full-Text Search
- Graph Queries
- query and query_table Functions
- Merge Statement for SCD Type 2
- Timestamp Issues
- Snippets
- Creating Synthetic Data
- Dutch Railway Datasets
- Sharing Macros
- Analyzing a Git Repository
- Importing Duckbox Tables
- Copying an In-Memory Database to a File
- Troubleshooting
- Glossary of Terms
- Browsing Offline
- Operations Manual
- Overview
- DuckDB's Footprint
- Installing DuckDB
- Logging
- User Agents
- Securing DuckDB
- Non-Deterministic Behavior
- Limits
- DuckDB Docker Container
- Development
- DuckDB Repositories
- Release Cycle
- Metrics
- Profiling
- Building DuckDB
- Overview
- Build Configuration
- Building Extensions
- Android
- Linux
- macOS
- Raspberry Pi
- Windows
- Python
- R
- Troubleshooting
- Unofficial and Unsupported Platforms
- Benchmark Suite
- Testing
- Internals
- Sitemap
- Live Demo
Vector is the container format used to store in-memory data during execution.
DataChunk is a collection of Vectors, used for instance to represent a column list in a PhysicalProjection operator.
Data Flow
DuckDB uses a vectorized query execution model. All operators in DuckDB are optimized to work on Vectors of a fixed size.
This fixed size is commonly referred to in the code as STANDARD_VECTOR_SIZE.
The default STANDARD_VECTOR_SIZE is 2048 tuples.
Vector Format
Vectors logically represent arrays that contain data of a single type. DuckDB supports different vector formats, which allow the system to store the same logical data with a different physical representation. This allows for a more compressed representation, and potentially allows for compressed execution throughout the system. Below the list of supported vector formats is shown.
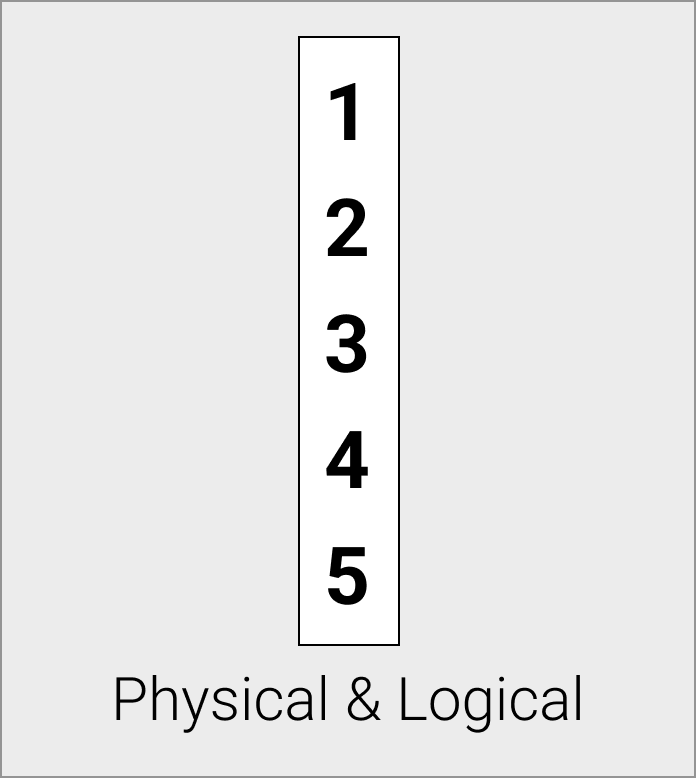
Flat Vectors
Flat vectors are physically stored as a contiguous array, this is the standard uncompressed vector format. For flat vectors the logical and physical representations are identical.
Constant Vectors
Constant vectors are physically stored as a single constant value.
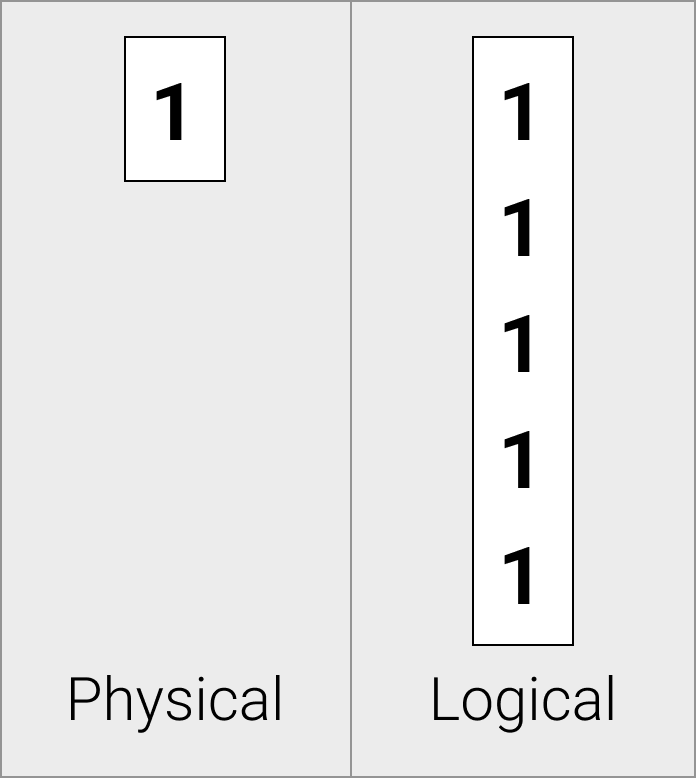
Constant vectors are useful when data elements are repeated – for example, when representing the result of a constant expression in a function call, the constant vector allows us to only store the value once.
SELECT lst || 'duckdb'
FROM range(1000) tbl(lst);
Since duckdb is a string literal, the value of the literal is the same for every row. In a flat vector, we would have to duplicate the literal 'duckdb' once for every row. The constant vector allows us to only store the literal once.
Constant vectors are also emitted by the storage when decompressing from constant compression.
Dictionary Vectors
Dictionary vectors are physically stored as a child vector, and a selection vector that contains indexes into the child vector.
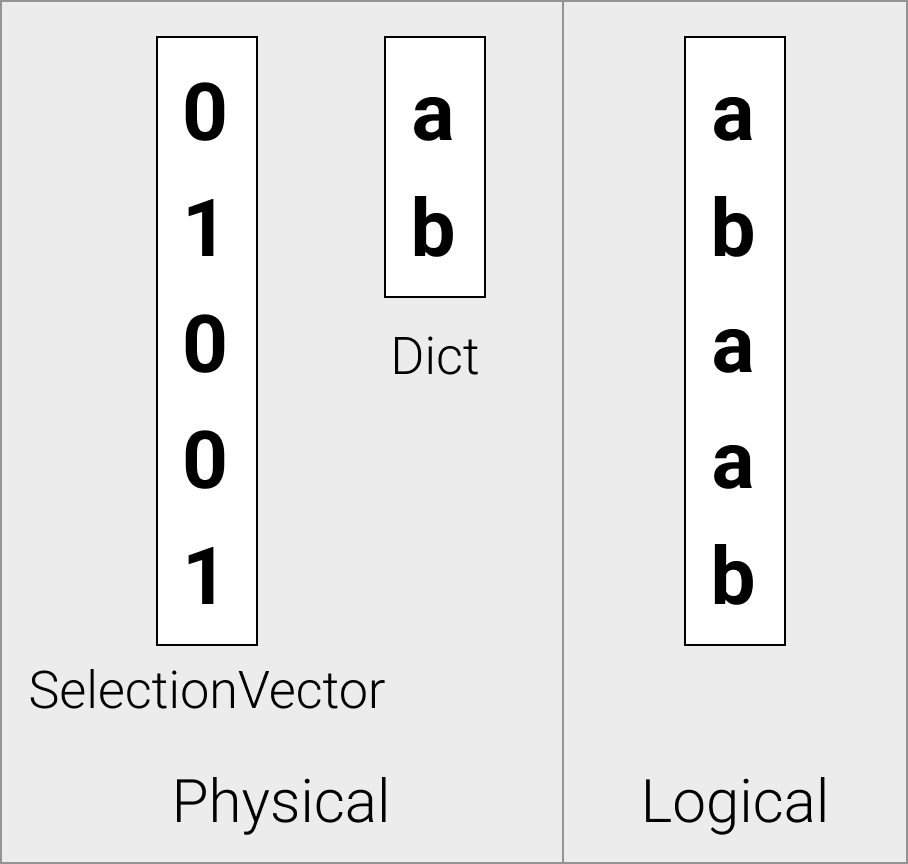
Dictionary vectors are emitted by the storage when decompressing from dictionary compression.
Just like constant vectors, dictionary vectors are also emitted by the storage. When deserializing a dictionary compressed column segment, we store this in a dictionary vector so we can keep the data compressed during query execution.
Sequence Vectors
Sequence vectors are physically stored as an offset and an increment value.
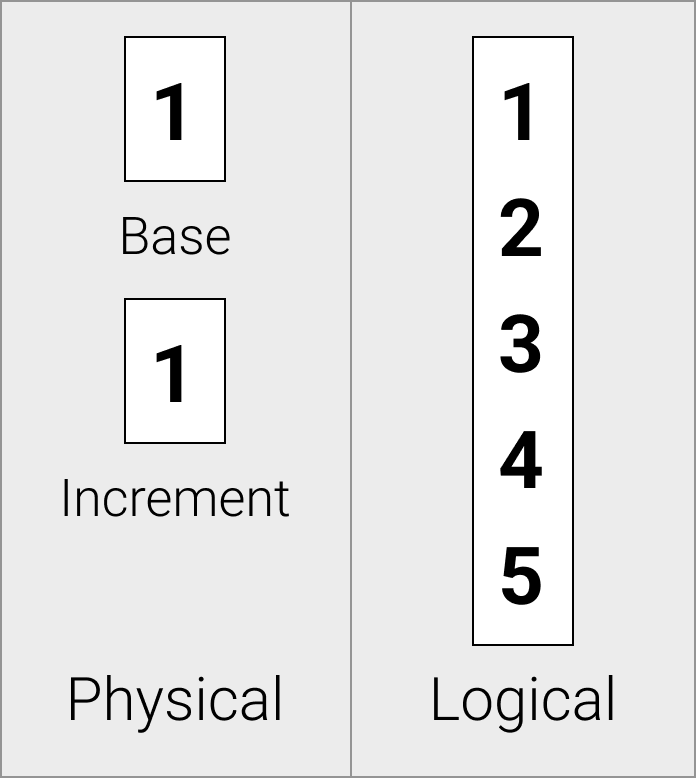
Sequence vectors are useful for efficiently storing incremental sequences. They are generally emitted for row identifiers.
Unified Vector Format
These properties of the different vector formats are great for optimization purposes, for example you can imagine the scenario where all the parameters to a function are constant, we can just compute the result once and emit a constant vector. But writing specialized code for every combination of vector types for every function is unfeasible due to the combinatorial explosion of possibilities.
Instead of doing this, whenever you want to generically use a vector regardless of the type, the UnifiedVectorFormat can be used. This format essentially acts as a generic view over the contents of the Vector. Every type of Vector can convert to this format.
Complex Types
String Vectors
To efficiently store strings, we make use of our string_t class.
struct string_t {
union {
struct {
uint32_t length;
char prefix[4];
char *ptr;
} pointer;
struct {
uint32_t length;
char inlined[12];
} inlined;
} value;
};
Short strings (<= 12 bytes) are inlined into the structure, while larger strings are stored with a pointer to the data in the auxiliary string buffer. The length is used throughout the functions to avoid having to call strlen and having to continuously check for null-pointers. The prefix is used for comparisons as an early out (when the prefix does not match, we know the strings are not equal and don't need to chase any pointers).
List Vectors
List vectors are stored as a series of list entries together with a child Vector. The child vector contains the values that are present in the list, and the list entries specify how each individual list is constructed.
struct list_entry_t {
idx_t offset;
idx_t length;
};
The offset refers to the start row in the child Vector, the length keeps track of the size of the list of this row.
List vectors can be stored recursively. For nested list vectors, the child of a list vector is again a list vector.
For example, consider this mock representation of a Vector of type BIGINT[][]:
{
"type": "list",
"data": "list_entry_t",
"child": {
"type": "list",
"data": "list_entry_t",
"child": {
"type": "bigint",
"data": "int64_t"
}
}
}
Struct Vectors
Struct vectors store a list of child vectors. The number and types of the child vectors is defined by the schema of the struct.
Map Vectors
Internally map vectors are stored as a LIST[STRUCT(key KEY_TYPE, value VALUE_TYPE)].
Union Vectors
Internally UNION utilizes the same structure as a STRUCT.
The first “child” is always occupied by the Tag Vector of the UNION, which records for each row which of the UNION's types apply to that row.