
Sorting on Insert for Fast Selective Queries

TL;DR: Sorting data when loading can speed up selective read queries by an order of magnitude, thanks to DuckDB's automatic min-max indexes (also known as zone maps). This approach applies to most columnar file formats and databases as well. This post unpacks the DuckDB file structure as an example of a columnar data format and gives practical advice for using sorting to improve the speed of queries.
The fastest way to read data is to not read data. It's as simple as that! This post is all about how to read as little data as possible to answer selective read queries.
Feel free to skip straight to the best practices!
Use Cases
The cases where these techniques are most useful are when read performance is more critical than write performance. In these cases, we can deliberately add ordering steps that will slow down our writes, but will greatly speed up our reads. This is often the case when data is pre-processed in the background, but read queries are customer facing in a dashboard or app.
Using sorting will be helpful in any of these situations:
- Your dataset is large and doesn't fit entirely in memory
- You only want to read a portion of your dataset for each query
- You access your data via HTTP(S)
- Your data lives in the cloud on object storage such as AWS S3
This overview describes the DuckDB file format, but thanks to DuckDB's partial reading support, these techniques can be generally applied to nearly any columnar file format or database. This is a great way to speed up querying Apache Parquet files on remote endpoints – including data lakes!
Stay tuned for a subsequent post covering advanced multi-column sorting!
How Does the DuckDB Format Help?
Let's build up some intuition around the structure of the DuckDB file format! DuckDB stores data in a single file. Each file is called a database (the DuckDB library is the database engine).
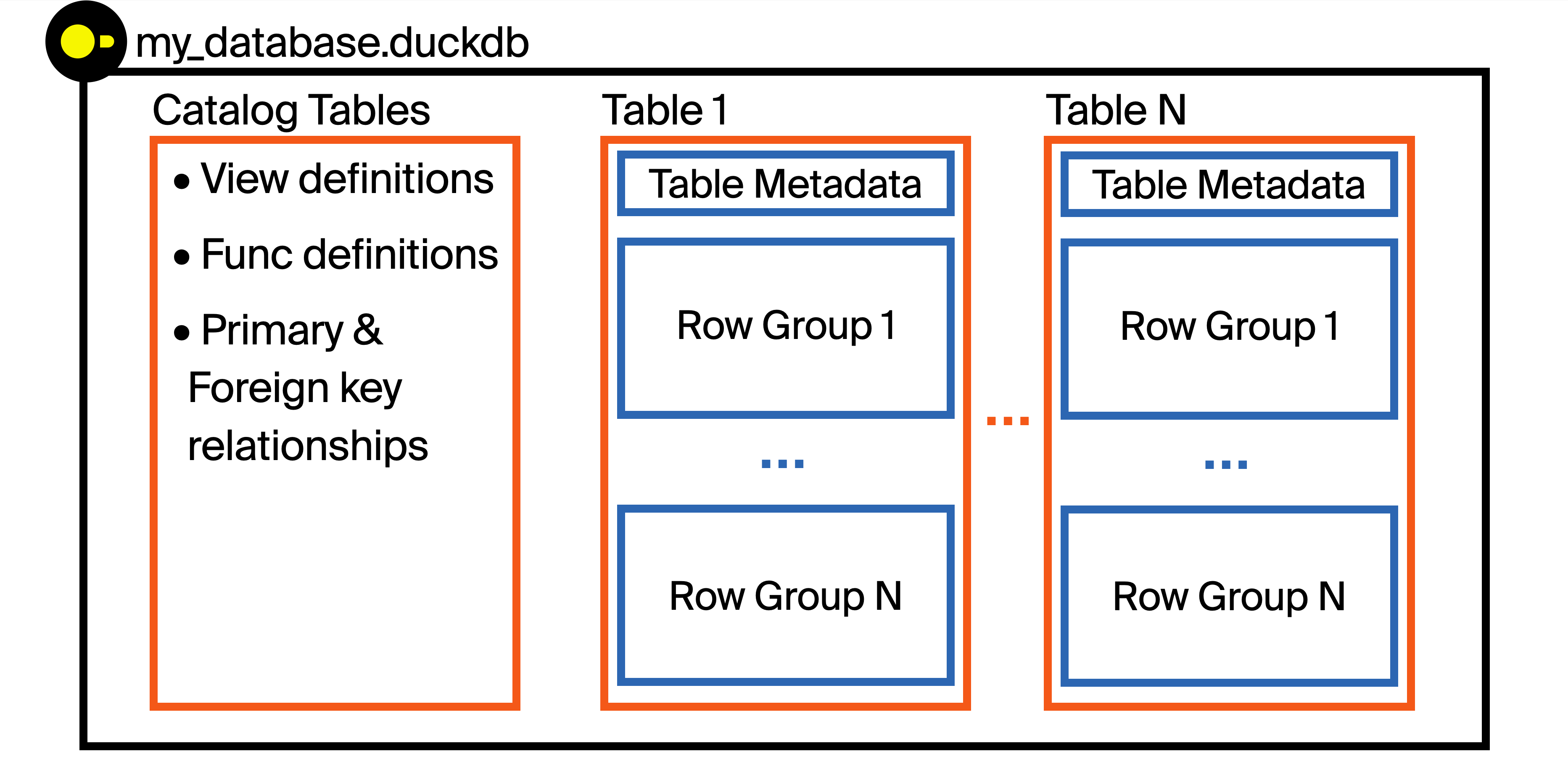
Each database file can store multiple tables, views, functions, indexes, and primary/foreign key relationships all in the same file. This has some key advantages for portability, but it also allows for the storage of more than just data – metadata can be stored as well. This metadata allows for the DuckDB engine to selectively read just portions of the DuckDB file as they are requested, which is key for handling larger than memory datasets and for the performance optimizations in this post!
DuckDB stores data in a columnar fashion (meaning that values within a column are stored together in the same set of blocks). However, columnar does not mean storing the entire column contiguously! Before storing data, DuckDB breaks tables up into chunks of rows called row groups. Each row group is 122 880 rows by default.
Next, we zoom in on Row Group 1 from Table 1 in the first diagram:
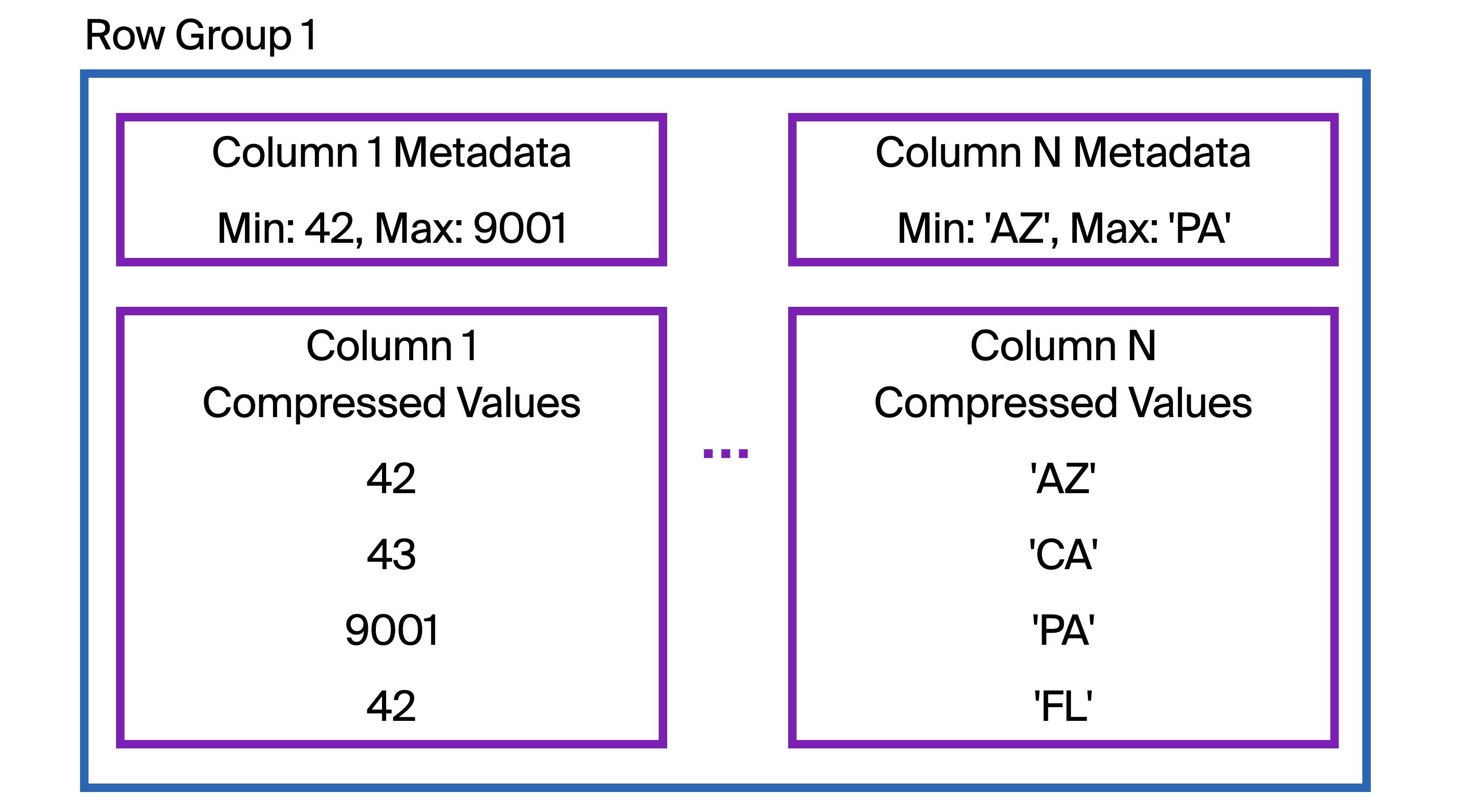
Within each row group, the data related to a single column is stored contiguously together on disk in one or more blocks. DuckDB compresses this data to reduce file size.
Using Zone Maps to Skip Reading Data
So, how does storing data in columns help with selective read queries? By itself, it does not! However, at the start of the column data stored within each row group, DuckDB also stores metadata about the column data being stored. This includes the minimum and maximum values of that column within that row group. We call these zone maps or min-max indexes.
When DuckDB receives a SQL query that contains a filter, before reading the column segments off of disk, it checks the metadata first. Could this filter value possibly fall within the minimum/maximum range of this column segment? If it is not possible, then DuckDB can skip reading the data in that entire row group.
For example, Column N in this example is storing the abbreviations for US states.
If we are querying data for the state of VA (Virginia), could this row group contain any data for VA?
Our query could be:
FROM "Table 1"
WHERE "Column N" = 'VA';
DuckDB's friendly SQL makes the traditional SQL
SELECT *optional!
DuckDB first checks the zone map (labeled Column N Metadata in the diagram).
Does VA fall within the range (alphabetically) of AZ to PA?
No it does not!
We can skip this entire row group.
If instead we were filtering for the state of NM (New Mexico), the zone map indicates that it is possible that NM data exists within this row group.
As a result, DuckDB will retrieve the entire column of data (possibly from a remote location) and check each row to see if any NM data exists.
According to the diagram, there is no NM data in this row group, so retrieving it and checking each row for a match would be unnecessary effort.
All 122 880 rows would need to be checked!
If only the zone map index did not cover such a large range of state abbreviations…
Strategically Skipping Data
Our goal is to sort our data so that the zone maps are as selective as possible for the columns we are interested in filtering.
If the min-max index of this row group only extended from AZ to CA, then the data would be far more likely to be skipped.
Said another way, each subset of the data we want to retrieve should only be stored in a few row groups.
We don't want to pull every row group and check every row!
Hopefully states that are early in the alphabet are all grouped together in the same row group, for example.
When executing selective queries, you could aim for pulling just a single row group! However, since DuckDB's multithreading model is based on row groups, you should still see high performance as long as the number of row groups is less than the number of threads (≈CPU cores) DuckDB is using.
Sorting Best Practices
There are many rules of thumb for how to best utilize min-max indexes, since their effectiveness is highly data and workload dependent. These are useful both in DuckDB as well as in other columnar formats like Apache Parquet or other columnar databases. Here are several approaches to consider!
When deciding which columns to sort, it is critical to examine the WHERE clauses of any read workloads.
Often the most important factor is which columns are used to filter most often.
A basic approach would be to sort by all columns that are used as filters, beginning with the columns used most often.
Another option if the workload involves filtering by multiple different columns is to consider sorting first by columns with the lowest cardinality (the fewest unique values).
For example, it may be helpful to sort by a broad customer_type prior to a unique customer_id.
It is often useful to only read recent data, so ensuring recent data is not spread throughout the table can improve performance. However, when ordering by timestamps, be mindful that timestamps are frequently very high cardinality. As a result, sorting by lower cardinality columns first may be helpful. You may be tempted to sort by timestamp first – resist that temptation! (or at least test out alternatives). It may be more beneficial to sort by a timestamp rounded to the nearest week, month, or year and then by other columns.
To benefit from min-max indexes, a
WHEREclause must filter directly on a specific column, not on a calculated expression. If an expression is used, it must be evaluated for each row, so no row groups can be skipped!
Additional Techniques
There are more ways to take full advantage of the min-max indexes in DuckDB!
Avoid Small Inserts
If a workload is inserting data in small batches or a single row at a time, there is not an opportunity to effectively sort the data when it is being inserted. Instead, the data will be sorted largely by insertion time, which will only provide effective pruning for time-based filters. If possible, bulk inserts or batching will allow the sorting to work more effectively for other columns. As an alternative, there can be a periodic re-sorting job, which is analogous to a re-indexing task in transactional systems.
Sort in Chunks
Sorting can be a computationally expensive operation for large tables. One way to reduce the amount of memory (or disk spill) required when sorting is to process the table in pieces by looping through multiple SQL statements, each filtered to a specific chunk. Since SQL does not have a looping construct, this would be handled by a host language (Python, Jinja templating, etc.). The pseudocode would be to:
CREATE OR REPLACE TABLE sorted_table AS
FROM unsorted_table
WITH NO DATA;
for chunk in chunks:
INSERT INTO sorted_table
FROM unsorted_table
WHERE chunking_column = chunk
ORDER BY other_columns...;
This will have the effect of sorting initially by the chunking column, and then by the other_columns.
It may also take longer to run (since the data must be scanned once per chunk), but memory use is likely to be much lower.
Sort the First Few Characters of Strings
Approximate sorting works well for improving read performance.
In the zone maps of VARCHAR columns, DuckDB stores just the first 8 bytes of the min and max string values.
As a result, there is no need to sort more than the first 8 bytes (8 ASCII characters)!
This has an added benefit of faster sorting, as the runtime of DuckDB's radix sort algorithm is sensitive to the length of strings (by design!).
The time complexity of the algorithm is O(nk), where n is the number of rows, and k is the width of the sorting key.
Sorting by just the first few characters of a VARCHAR can be quicker and less compute intensive while achieving similar read performance.
DuckDB's VARCHAR data type also inlines strings when they are under 12 bytes, so working with short strings is faster for that reason as well.
For example:
CREATE OR REPLACE TABLE sorted_table AS
FROM unsorted_table
ORDER BY varchar_column_to_sort[:8];
DuckDB's friendly SQL allows bracket notation for string slicing!
Filter by More Columns
Adding filters to a WHERE clause can be helpful if those columns being filtered have any kind of approximate order.
For example, instead of just filtering by customer_id, if the table is sorted by customer_type, include that in the query also.
Often, if the customer_id is known at query time, it is possible to know other metadata as well.
Adjust the Row Group Size
One parameter that can be tuned for specific workloads is the number of rows within a row group (the ROW_GROUP_SIZE).
If there are many unique values within a column being filtered on, then a smaller number of rows per row group could reduce the total number of rows that must be scanned.
However, there is an overhead of checking metadata more often when row groups are smaller, so there is a tradeoff.
A larger row group size may actually be preferable if a table is particularly large and queries are very selective. For example, if querying a large fact table with years of history, but filtering to only the last week of data. Larger row group sizes reduce the number of metadata checks that are necessary to reach the recent data. However, each row group is larger, so there is a tradeoff there as well.
To adjust the row group size, pass in a parameter when attaching a database. Note that a row group size should be a power of 2. The minimum row group size is 2 048, the vector size of DuckDB.
ATTACH './smaller_row_groups.duckdb' (ROW_GROUP_SIZE 8_192);
Sneak Peak of the Next Post in the Series
A subsequent post in this series will cover advanced sorting techniques. These can boost performance if multiple reader workloads with different filters are querying the same dataset. For example, what if I need to filter by US state for some queries, but by customer last name for others? Additionally, sorting by rounded time buckets (day, month, or year) and then by other columns can be helpful when only recent data is needed.
Microbenchmarks will show the 10× performance benefits that were mentioned at the start of this post! The post will also provide ways to measure how effectively a table is sorted along various columns.
Conclusion
Ordering data upon insert can significantly speed up read queries that include filters. Once your dataset becomes large or you are storing it remotely, consider applying these techniques. Plus, these approaches can be used in nearly any columnar file format or database!
Happy analyzing!

