Memory Management in DuckDB

Memory is an important resource when processing large amounts of data. Memory is a fast caching layer that can provide immense speed-ups to query processing. However, memory is finite and expensive, and when working with large data sets there is generally not enough memory available to keep all necessary data structures cached. Managing memory effectively is critical for a high-performance query engine – as memory must be utilized in order to provide that high performance, but we must be careful so that we do not use excessive memory which can cause out-of-memory errors or can cause the ominous OOM killer to zap the process out of existence.
DuckDB is built to effectively utilize available memory while avoiding running out of memory:
- The streaming execution engine allows small chunks of data to flow through the system without requiring entire data sets to be materialized in memory.
- Data from intermediates can be spilled to disk temporarily in order to free up space in memory, allowing computation of complex queries that would otherwise exceed the available memory.
- The buffer manager caches as many pages as possible from any attached databases without exceeding the pre-defined memory limits.
In this blog post we will cover these aspects of memory management within DuckDB – and provide examples of where they are utilized.
Streaming Execution
DuckDB uses a streaming execution engine to process queries. Data sources, such as tables, CSV files or Parquet files, are never fully materialized in memory. Instead, data is read and processed one chunk at a time. For example, consider the execution of the following query:
SELECT
UserAgent,
count(*)
FROM 'hits.csv'
GROUP BY UserAgent;
Instead of reading the entire CSV file at once, DuckDB reads data from the CSV file in pieces, and computes the aggregation incrementally using the data read from those pieces. This happens continuously until the entire CSV file is read, at which point the entire aggregation result is computed.
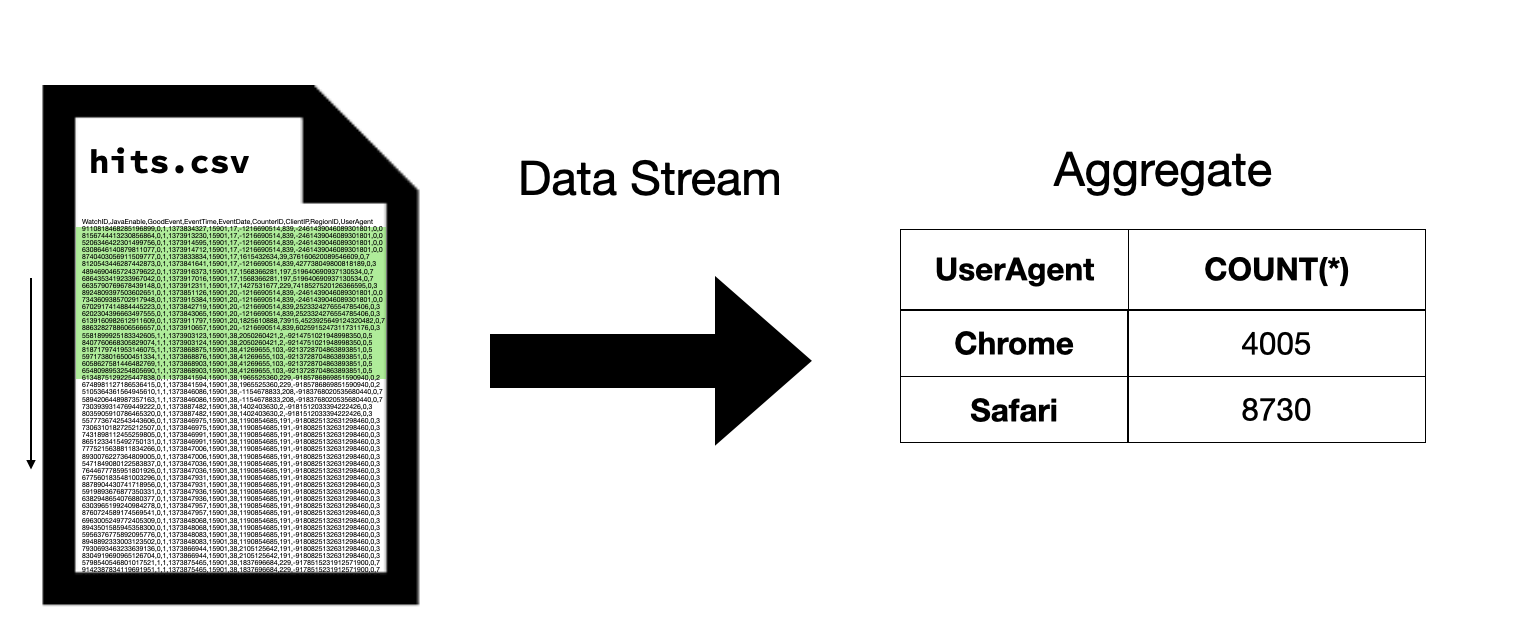
In the above example we are only showing a single data stream. In practice, DuckDB uses multiple data streams to enable multi-threaded execution – each thread executes its own data stream. The aggregation results of the different threads are combined to compute the final result.
While streaming execution is conceptually simple, it is powerful, and is sufficient to provide larger-than-memory support for many simple use cases. For example, streaming execution enables larger-than-memory support for:
- Computing aggregations where the total number of groups is small
- Reading data from one file and writing to another (e.g., reading from CSV and writing to Parquet)
- Computing a Top-N over the data (where N is small)
Note that nothing needs to be done to enable streaming execution – DuckDB always processes queries in this manner.
Intermediate Spilling
While streaming execution enables larger-than-memory processing for simple queries, there are many cases where streaming execution alone is not sufficient.
In the previous example, streaming execution enabled larger-than-memory processing because the computed aggregate result was very small – as there are very few unique user agents in comparison to the total number of web requests. As a result, the aggregate hash table would always remain small, and never exceed the amount of available memory.
Streaming execution is not sufficient if the intermediates required to process a query are larger than memory. For example, suppose we group by the source IP in the previous example:
SELECT
IPNetworkID,
count(*)
FROM 'hits.csv'
GROUP BY IPNetworkID;
Since there are many more unique source IPs, the hash table we need to maintain is significantly larger. If the size of the aggregate hash table exceeds memory, the streaming execution engine is not sufficient to prevent out-of-memory issues.
Larger-than-memory intermediates can happen in many scenarios, in particular when executing more complex queries. For example, the following scenarios can lead to larger-than-memory intermediates:
- Computing an aggregation with many unique groups
- Computing an exact distinct count of a column with many distinct values
- Joining two tables together that are both larger than memory
- Sorting a larger-than-memory dataset
- Computing a complex window over a larger-than-memory table
DuckDB deals with these scenarios by disk spilling. Larger-than-memory intermediates are (partially) written to disk in the temporary directory when required. While powerful, disk spilling reduces performance – as additional I/O must be performed. For that reason, DuckDB tries to minimize disk spilling. Disk spilling is adaptively used only when the size of the intermediates increases past the memory limit. Even in those scenarios, as much data is kept in memory as possible to maximize performance. The exact way this is done depends on the operators and is detailed in other blog posts (aggregation, sorting).
The memory_limit setting controls how much data DuckDB is allowed to keep in memory. By default, this is set to 80% of the physical RAM of your system (e.g., if your system has 16 GB RAM, this defaults to 12.8 GB). The memory limit can be changed using the following command:
SET memory_limit = '4GB';
The location of the temporary directory can be chosen using the temp_directory setting, and is by default the connected database with a .tmp suffix (e.g., database.db.tmp), or only .tmp if connecting to an in-memory database. The maximum size of the temporary directory can be limited using the max_temp_directory_size setting, which defaults to 90% of the remaining disk space on the drive where the temporary files are stored. These settings can be adjusted as follows:
SET temp_directory = '/tmp/duckdb_swap';
SET max_temp_directory_size = '100GB';
If the memory limit is exceeded and disk spilling cannot be used, either because disk spilling is explicitly disabled, the temporary directory size exceeds the provided limit, or a system limitation means that disk spilling cannot be used for a given query – an out-of-memory error is reported and the query is canceled.
Buffer Manager
Another core component of memory management in DuckDB is the buffer manager. The buffer manager is responsible for caching pages from DuckDB's own persistent storage. Conceptually the buffer manager works in a similar fashion to the intermediate spilling. Pages are kept in memory as much as possible, and evicted from memory when space is required for other data structures. The buffer manager abides by the same memory limit as any intermediate data structures. Pages in the buffer manager can be freed up to make space for intermediate data structures, or vice versa.
There are two main differences between the buffer manager and intermediate data structures:
- As the buffer manager caches pages that already exist on disk (in DuckDB's persistent storage) – they do not need to be written to the temporary directory when evicted. Instead, when they are required again, they can be re-read from the attached storage file directly.
- Query intermediates have a natural life-cycle, namely when the query is finished processing the intermediates are no longer required. Pages that are buffer managed from the persistent storage are useful across queries. As such, the pages kept by the buffer manager are kept cached until either the persistent database is closed, or until space must be freed up for other operations.
The performance boost of the buffer manager depends on the speed of the underlying storage medium. When data is stored on a very fast disk, reading data is fast and the speed-up is minimal. When data is stored on a network drive or read over http/S3, reading requires performing network requests, and the speed-up can be very large.
Profiling Memory Usage
DuckDB contains a number of tools that can be used to profile memory usage.
The duckdb_memory() function can be used to inspect which components of the system are using memory. Memory used by the buffer manager is labeled as BASE_TABLE, while query intermediates are divided into separate groups.
FROM duckdb_memory();
┌──────────────────┬────────────────────┬─────────────────────────┐
│ tag │ memory_usage_bytes │ temporary_storage_bytes │
│ varchar │ int64 │ int64 │
├──────────────────┼────────────────────┼─────────────────────────┤
│ BASE_TABLE │ 168558592 │ 0 │
│ HASH_TABLE │ 0 │ 0 │
│ PARQUET_READER │ 0 │ 0 │
│ CSV_READER │ 0 │ 0 │
│ ORDER_BY │ 0 │ 0 │
│ ART_INDEX │ 0 │ 0 │
│ COLUMN_DATA │ 0 │ 0 │
│ METADATA │ 0 │ 0 │
│ OVERFLOW_STRINGS │ 0 │ 0 │
│ IN_MEMORY_TABLE │ 0 │ 0 │
│ ALLOCATOR │ 0 │ 0 │
│ EXTENSION │ 0 │ 0 │
├──────────────────┴────────────────────┴─────────────────────────┤
│ 12 rows 3 columns │
└─────────────────────────────────────────────────────────────────┘
The duckdb_temporary_files function can be used to examine the current contents of the temporary directory.
FROM duckdb_temporary_files();
┌────────────────────────────────┬───────────┐
│ path │ size │
│ varchar │ int64 │
├────────────────────────────────┼───────────┤
│ .tmp/duckdb_temp_storage-0.tmp │ 967049216 │
└────────────────────────────────┴───────────┘
Conclusion
Memory management is critical for a high-performance analytics engine. DuckDB is built to take advantage of any available memory to speed up query processing, while gracefully dealing with larger-than-memory datasets using intermediate spilling. Memory management is still an active area of development and has continuously improved across DuckDB versions. Amongst others, we are working on improving memory management for complex queries that involve multiple operators with larger-than-memory intermediates.

