Adoption Metrics and Benchmark Results for DuckDB v1.4 LTS
TL;DR: The DuckDB landing page makes some strong claims about DuckDB's popularity. In this blog post, we show evidence for these claims.
#1 on ClickBench
On October 9, 2025, DuckDB's in-memory variant hit #1 on the popular ClickBench database benchmark:

This result was made possible due several performance optimizations in DuckDB v1.4.
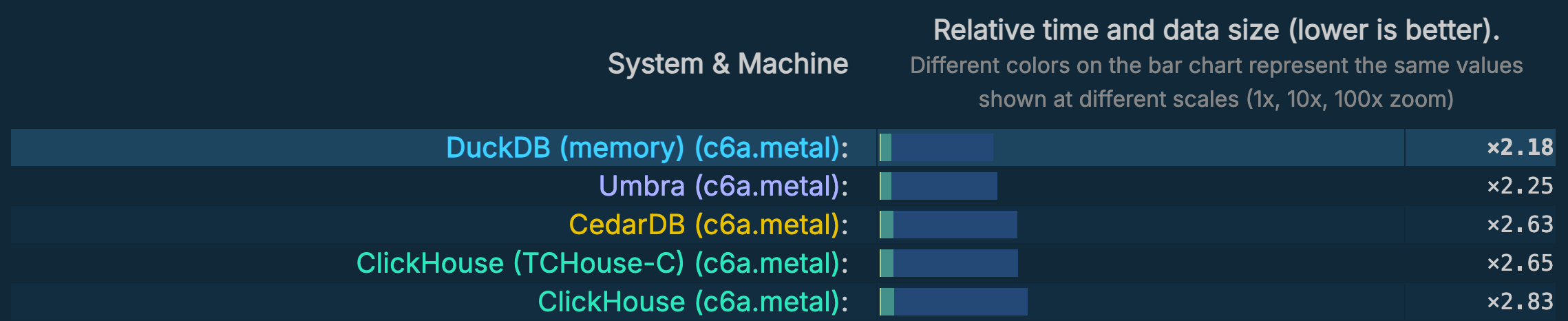
Update As of October 26, the rules of ClickBench changed. The new rules prevent in-memory databases from showing “cold” (and “combined”) results. After this change, DuckDB is the #1 open-source system in hot runs, closely trailing the leader in that category, Umbra, a closed-source research prototype.
#3 Most Admired System on Stack Overflow
In Stack Overflow's 2024 Developer Survey, DuckDB was named among the top-3 most admired database systems. In the 2025 survey, it achieved position #4 (just 0.2% behind SQLite) but it made up for this by a significant increase in usage, which jumped from 1.4% in 2024 to 3.3% in 2025.
20+ Fortune-100 Companies Use DuckDB
We estimated the number of Fortune-100 companies who use DuckDB by cross-checking self-reported affiliations in the DuckDB issue tracker against a list of Fortune-100 companies.
25M+ Downloads / Month
DuckDB's Python packages has almost 25 million monthly downloads on PyPI alone. This is complemented with the downloads of other popular clients such as the CLI, Go, Node.js, Java, R, Rust and so on.
TPC-H SF 100,000
DuckDB is not only fast but it is also scalable. We have recently run the queries of the TPC-H workload on the scale factor 100,000 dataset, which is equivalent to 100,000 GB of CSV files. Obviously, processing such a dataset size requires the ability to spill to disk.
We ran the experiment on an i8g.48xlarge EC2 instance, which has 1.5 TB of RAM and 192 CPU cores (AWS Graviton4, Arm64). This instance has 12 NVMe SSD disks, each 3750 GB in size. We created a RAID-0 array from them to have a single 45 TB partition and formatted it using XFS.
We generated the dataset with the tpchgen-cli tool, a pure Rust implementation of the TPC-H generator. We configured the generator to produce chunks of Parquet files and loaded them into DuckDB. The final DuckDB database was about 27 TB in size (as a single file!).
DuckDB completed all 22 queries of the benchmark using its larger-than-memory processing. For some queries, this required spilling about 7 terabytes of data to disk. The median query runtime was 1.19 hours and the geometric mean runtime was 1.13 hours.

