Lightweight Text Analytics Workflows with DuckDB
TL;DR: In this post, we demonstrate how to use DuckDB for keyword, full-text, and semantic similarity search with embeddings.
Introduction
Text analytics is a central component of many modern data workflows, covering tasks such as keyword matching, full-text search, and semantic comparison. Conventional tools frequently require complex pipelines and substantial infrastructure, which can pose significant challenges. DuckDB offers a high-performance SQL engine that simplifies and streamlines text analytics. In this post, we will demonstrate how to leverage DuckDB to efficiently perform advanced text analytics in Python.
The following implementation is executed in a marimo Python notebook, which is available on GitHub, in our examples repository.
Data Preparation
We will be working with a public dataset, available on Hugging Face, which contains English Twitter messages and their classification to one of the following emotions: anger, fear, joy, love, sadness, and surprise.
With DuckDB we are able to access Hugging Face datasets via the hf:// prefix:
from_hf_rel = conn.read_parquet(
"hf://datasets/dair-ai/emotion/unsplit/train-00000-of-00001.parquet",
file_row_number=True
)
from_hf_rel = from_hf_rel.select("""
text,
label as emotion_id,
file_row_number as text_id
""")
from_hf_rel.to_table("text_emotions")
How to access Hugging Face datasets with DuckDB is detailed in the post “Access 150k+ Datasets from Hugging Face with DuckDB”.
In the above data we have available only the identifier of an emotion (emotion_id), without its descriptive information. Therefore, from the list provided in the dataset description, we create a reference table by unnesting the Python list and retrieving the index for each value with the generate_subscripts function:
emotion_labels = ["sadness", "joy", "love", "anger", "fear", "surprise"]
from_labels_rel = conn.values([emotion_labels])
from_labels_rel = from_labels_rel.select("""
unnest(col0) as emotion,
generate_subscripts(col0, 1) - 1 as emotion_id
""")
from_labels_rel.to_table("emotion_ref")
Last we define a relation, by joining the two tables:
text_emotions_rel = conn.table("text_emotions").join(
conn.table("emotion_ref"), condition="emotion_id"
)
By executing
text_emotions_rel.to_view("text_emotions_v", replace=True)a view with the nametext_emotions_vwill be created, which can be used in SQL cells.
We plot on a bar chart the emotion distribution to have an initial understanding of our data:
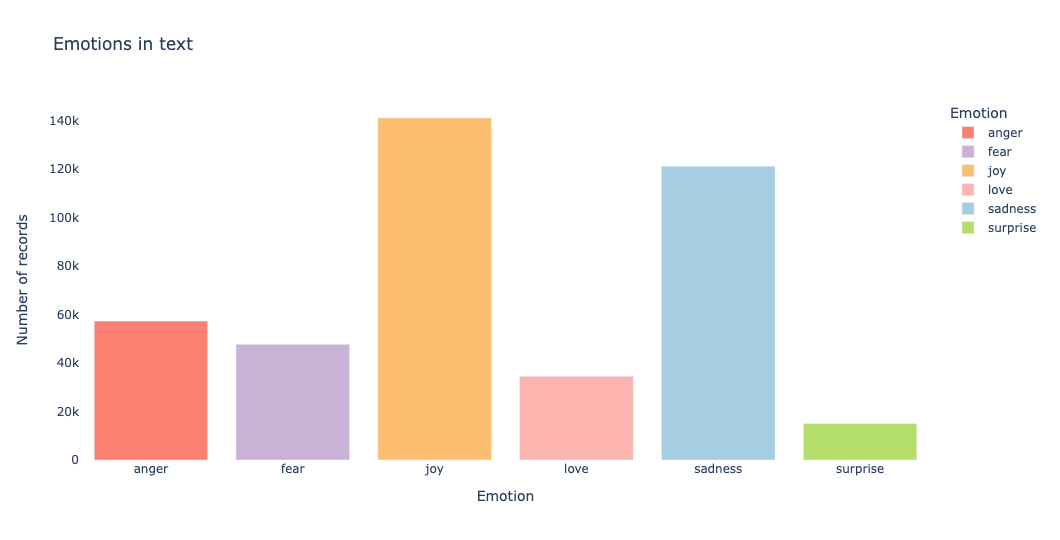
Keyword Search
Keyword search is the most basic form of text retrieval, matching exact words or phrases in text fields using SQL conditions such as CONTAINS, ILIKE, or other DuckDB text functions.
It is fast, requires no preprocessing, and works well for structured queries like filtering logs, matching tags, or finding product names.
For example, getting the texts and their emotion label containing the phrase excited to learn is a matter of applying filter on the relation defined above:
text_emotions_rel.filter("text ilike '%excited to learn%'").select("""
emotion,
substring(
text,
position('excited to learn' in text),
len('excited to learn')
) as substring_text
""")
┌─────────┬──────────────────┐
│ emotion │ substring_text │
│ varchar │ varchar │
├─────────┼──────────────────┤
│ sadness │ excited to learn │
│ joy │ excited to learn │
│ joy │ excited to learn │
│ fear │ excited to learn │
│ fear │ excited to learn │
│ joy │ excited to learn │
│ joy │ excited to learn │
│ sadness │ excited to learn │
└─────────┴──────────────────┘
One common step in text processing is to split text into tokens (keywords), where raw text is broken down into smaller units (typically words), that can be analyzed or indexed. This process, known as tokenization, helps convert unstructured text into a structured form suitable for keyword search. In DuckDB this process can be implemented with the regexp_split_to_table function, which will split the text based on the provided regex and return each keyword on a row.
This step is case sensitive, therefore it is important to convert all text to a consistent case (by applying
lcaseorucase) before processing.
In the below code snippet we select all the keywords by splitting the text on one or more non-word characters (anything except [a-zA-Z0-9_]):
text_emotions_tokenized_rel = text_emotions_rel.select("""
text_id,
emotion,
regexp_split_to_table(text, '\\W+') as token
""")
In the tokenization step, we usually exclude common words (such as and, the), called stopwords. In DuckDB we implement the exclusion by applying an ANTI JOIN on a curated CSV file hosted on GitHub:
english_stopwords_rel = duckdb_conn.read_csv(
"https://raw.githubusercontent.com/stopwords-iso/stopwords-en/refs/heads/master/stopwords-en.txt",
header=False,
).select("column0 as token")
text_emotions_tokenized_rel.join(
english_stopwords_rel,
condition="token",
how="anti",
).to_table("text_emotion_tokens")
Now that we have tokenized and cleaned the text, we can implement keyword search by ranking the match with similarity functions, such as Jaccard:
text_token_rel = conn.table(
"text_emotion_tokens"
).select("token, emotion, jaccard(token, 'learn') as jaccard_score")
text_token_rel = text_token_rel.max(
"jaccard_score",
groups="emotion, token",
projected_columns="emotion, token"
)
text_token_rel.order("3 desc").limit(10)
┌──────────┬─────────┬────────────────────┐
│ emotion │ token │ max(jaccard_score) │
│ varchar │ varchar │ double │
├──────────┼─────────┼────────────────────┤
│ fear │ learn │ 1.0 │
│ surprise │ learn │ 1.0 │
│ love │ learn │ 1.0 │
│ joy │ lerna │ 1.0 │
│ sadness │ learn │ 1.0 │
│ fear │ learner │ 1.0 │
│ anger │ learn │ 1.0 │
│ joy │ leaner │ 1.0 │
│ fear │ allaner │ 1.0 │
│ anger │ learner │ 1.0 │
├──────────┴─────────┴────────────────────┤
│ 10 rows 3 columns │
└─────────────────────────────────────────┘
We can also visualize the data to gain insights. One simple and effective approach is to plot the most frequently used words. By counting token occurrences across the dataset and displaying them in bubble plots, we can quickly identify dominant themes, repeated keywords, or unusual patterns in the text. For example, we plot the data by using a scatter facet plot per emotion:
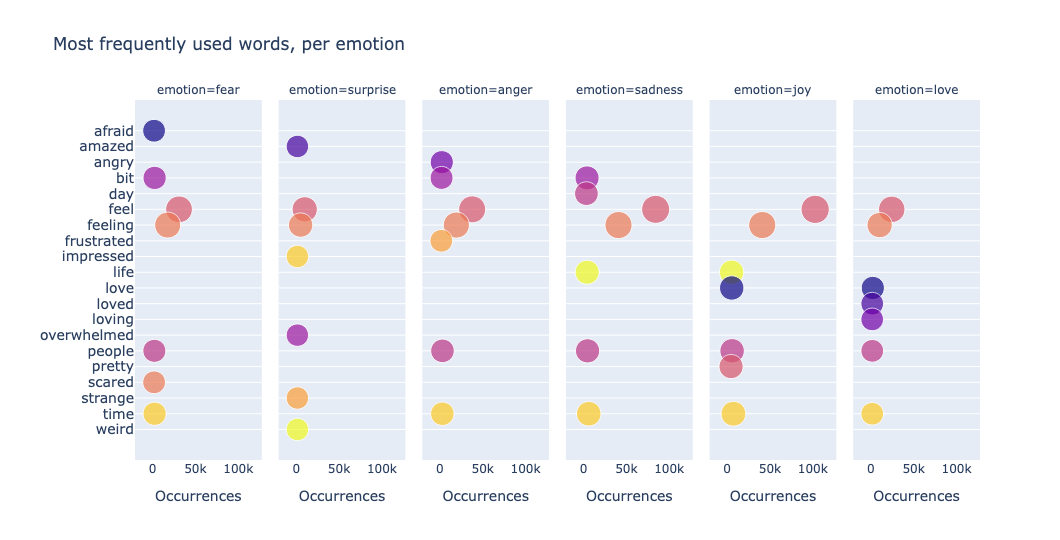
From the above plot, we observe repeated keywords, such as feel - feeling, love - loved - loving. In order to de-duplicate such data, we need to look at the word stem rather than at the word itself. This brings us to full-text search.
Full-Text Search
The Full-Text Search (FTS) DuckDB extension is an experimental extension, which implements two main full-text search functionalities:
- the
stemfunction, to retrieve the word stem; - the
match_bm25function, to calculate the Best Match score.
By applying stem to the token column, we can now visualize the most frequently used word stem in our data:
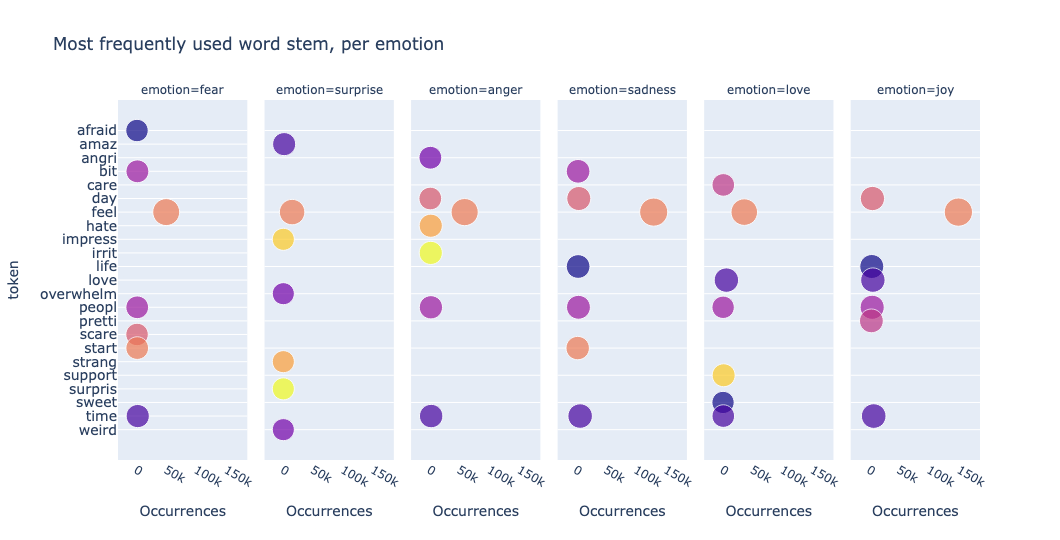
We observe that feel and love appear only once and new word stems are plotted, such as support, surpris.
While the stem function can be used standalone, the match_bm25 one requires the build of a FTS index, a special index that allows fast and efficient searching of text by indexing the words (tokens) in a column:
conn.sql("""
PRAGMA create_fts_index(
"text_emotions",
text_id,
"text",
stemmer = 'english',
stopwords = 'english_stopwords',
ignore = '(\\.|[^a-z])+',
strip_accents = 1,
lower = 1,
overwrite = 1
)
""")
In the FTS index creation we are using the same list of English stopwords as in the tokenization process, by saving it into a table, named english_stopwords. The index is case insensitive due to the lower parameter, which will lowercase the text automatically.
Warning The index can be created only on tables and it requires a unique identifier of the text. It also needs to be rebuilt when the underlying data has been modified.
Once the index has been created, we can rank the match between the text column and the phrase excited to learn:
text_emotions_rel
.select("""
emotion,
text,
emotion_color,
fts_main_text_emotions.match_bm25(
text_id,
'excited to learn'
)::decimal(3, 2) as bm25_score
""")
.order("bm25_score desc")
.limit(10)
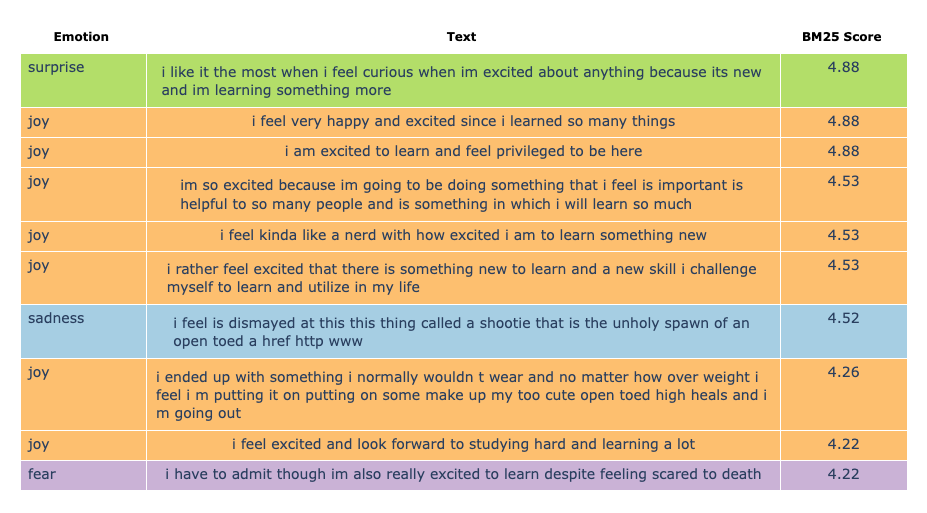
Out of the 10 returned texts, displayed above in a table plot, 2 are poor matches to our search input; likely due to BM25 scoring being skewed by common terms or differences in document length.
Semantic Search
Compared to keyword and full-text search, semantic search takes into account the meaning and context of the text. Instead of just looking for exact words, it uses techniques like vector embeddings to capture the underlying concepts. Semantic search, which is case insensitive, can be implemented in DuckDB, by making use of the (also experimental) Vector Similarity Search extension.
The vector embeddings of a (list of) text can be calculated with the sentence-transformers library and the pre-trained model all-MiniLM-L6-v2:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
def get_text_embedding_list(list_text: list[str]):
"""
Return the list of normalized vector embeddings for list_text.
"""
return model.encode(list_text, normalize_embeddings=True)
For example, get_text_embedding_list(['excited to learn']) will return:
array([[ 3.14795598e-02, -6.66208193e-02, 1.05058309e-02,
4.12571728e-02, -8.67664907e-03, -1.79746319e-02,
...
-2.50727013e-02, -3.00881546e-03, 1.55055271e-02]], dtype=float32)
We register the model inference function as a Python User Defined Function and create a table with a column of type FLOAT[384] to load the embeddings into:
conn.create_function(
"get_text_embedding_list",
get_text_embedding_list,
return_type='FLOAT[384][]'
)
conn.sql("""
create table text_emotion_embeddings (
text_id integer,
text_embedding FLOAT[384]
)
""")
With the Python UDF, we save, in batches, the model output in text_emotion_embeddings:
for i in range(num_batches):
selection_query = (
duckdb_conn.table("text_emotions")
.order("text_id")
.limit(batch_size, offset=batch_size*i)
.select("*")
)
(
selection_query.aggregate("""
array_agg(text) as text_list,
array_agg(text_id) as id_list,
get_text_embedding_list(text_list) as text_emb_list
""").select("""
unnest(id_list) as text_id,
unnest(text_emb_list) as text_embedding
""")
).insert_into("text_emotion_embeddings")
We wrote about model inference in DuckDB in the post Machine Learning Prototyping with DuckDB and scikit-learn.
We can now perform semantic search by using the cosine distance between the vector embedding of our search text, excited to learn, and the embedding of the text field:
input_text_emb_rel = conn.sql("""
select get_text_embedding_list(['excited to learn'])[1] as input_text_embedding
""")
text_emotions_rel
.join(conn.table("text_emotion_embeddings"), condition="text_id")
.join(input_text_emb_rel, condition="1=1")
.select("""
text,
emotion,
emotion_color,
array_cosine_distance(
text_embedding,
input_text_embedding
)::decimal(3, 2) as cosine_distance_score
""")
.order("cosine_distance_score asc")
.limit(10)
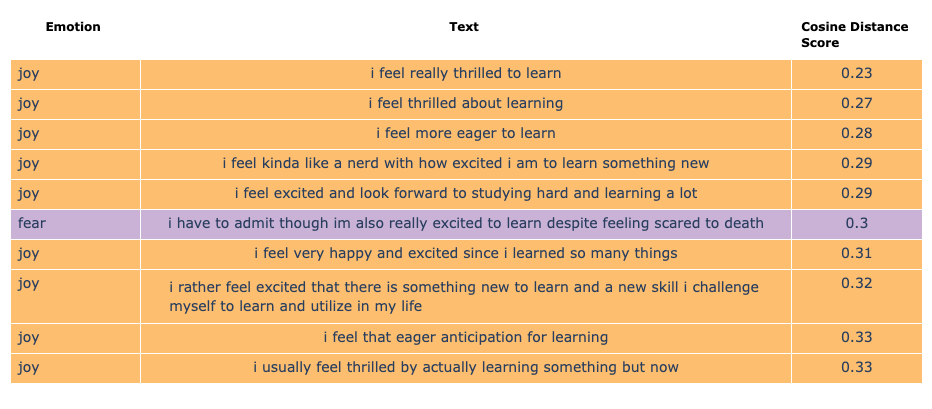
Interesting to observe that the phrase i am excited to learn and feel privileged to be here didn't make it in the top 10 results in our semantic search!
Similarity Joins
Vector embeddings are most known for their usability in search engines, but they can be used in a variety of text analytics use cases, such as topic grouping, classification or semantic matching between documents. The VSS extension provides vector similarity joins, which can be used to conduct these types of analytics.
For example, we show in the below heatmap chart the number of texts for each combination of emotion labels, where the x-axis corresponds to the semantic matching between the text and the emotion, the y-axis to the classified emotion, and the color indicates the count of texts assigned to each pair:
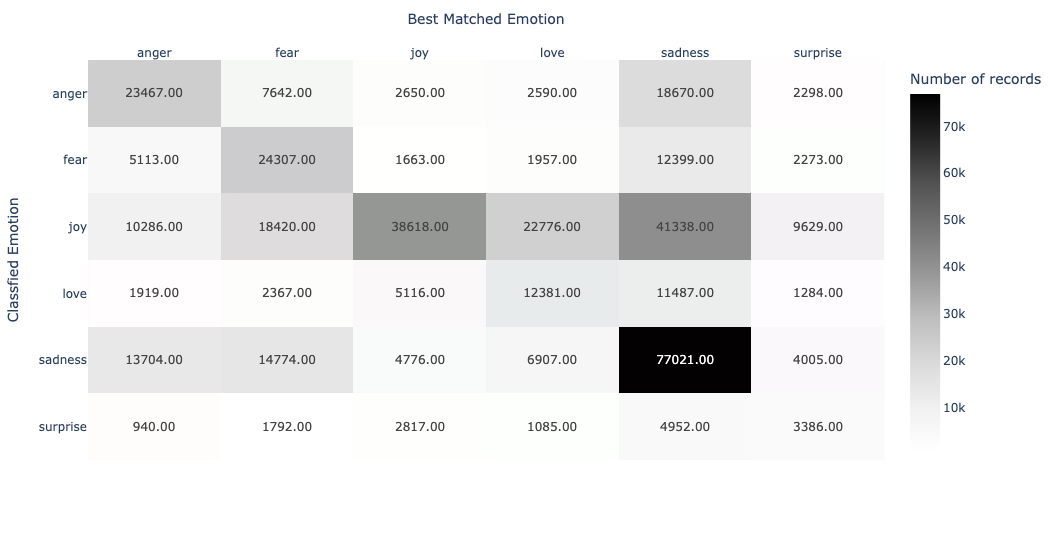
It is particularly noticeable that from the 6 emotions, only sadness has a strong semantic match with the text classified with the same label. As with full-text search, semantic search is affected by differences in document length (in this case the emotion keyword versus a text).
Hybrid Search
While each type of search has its own applicability, we observed that some results are not as expected:
- keyword search and full-text search do not take word meaning into account;
- semantic search scored synonyms higher than the search text.
In practice, the three search methods are combined and used to perform a “hybrid search”, in order to improve the search relevance and accuracy. We start by calculating the score for each type of search, by implementing custom logic, such as a check on the emotion:
if(
emotion = 'joy' and contains(text, 'excited to learn'),
1,
0
) exact_match_score,
fts_main_text_emotions.match_bm25(
text_id,
'excited to learn'
)::decimal(3, 2) as bm25_score,
array_cosine_similarity(
text_embedding,
input_text_embedding
)::decimal(3, 2) as cosine_similarity_score
The BM25 score is ranked in descending order and the cosine distance in ascending order. In hybrid search, we use the array_cosine_similarity score to ensure the same sort order (in this case descending).
cosine similarity = 1 - cosine distance
Because the BM25 score can be, in theory, unbounded, we need to scale the score to the interval [0, 1] by implementing the min-max normalization:
max(bm25_score) over () as max_bm25_score,
min(bm25_score) over () as min_bm25_score,
(bm25_score - min_bm25_score) / nullif((max_bm25_score - min_bm25_score), 0) as norm_bm25_score
The hybrid search score is calculated by applying a weight to the BM25 and cosine similarity scores:
if(
exact_match_score = 1,
exact_match_score,
cast(
0.3 * coalesce(norm_bm25_score, 0) +
0.7 * coalesce(cosine_similarity_score, 0)
as
decimal(3, 2)
)
) as hybrid_score
And here are the results! Much better, don't you think?

Conclusion
In this post, we showed how DuckDB can be used for text analytics by combining keyword, full-text, and semantic search techniques. Using the experimental fts and vss extensions with the sentence-transformers library, we demonstrated how DuckDB can support both traditional and modern text analytics workflows.

