DuckDB's CSV Reader and the Pollock Robustness Benchmark: Into the CSV Abyss
TL;DR: DuckDB ships with a fast and robust CSV reader, which – we believe – can consume most CSV files found in the wild. To empirically evaluate this, we used the Pollock Benchmark, a state-of-the-art test suite designed to measure how well CSV readers can operate on non-standard files, and found that DuckDB ranks #1.

The Sorry State of the CSV Landscape
It is a well-known fact that CSV files come in all shapes and forms. While there is a well-defined standard, it is common for systems to export data without following even the basic rules of CSV construction. For example, Rabobank, one of the biggest banks in the Netherlands, exports the financial data of its clients with unescaped quotes in quoted values.
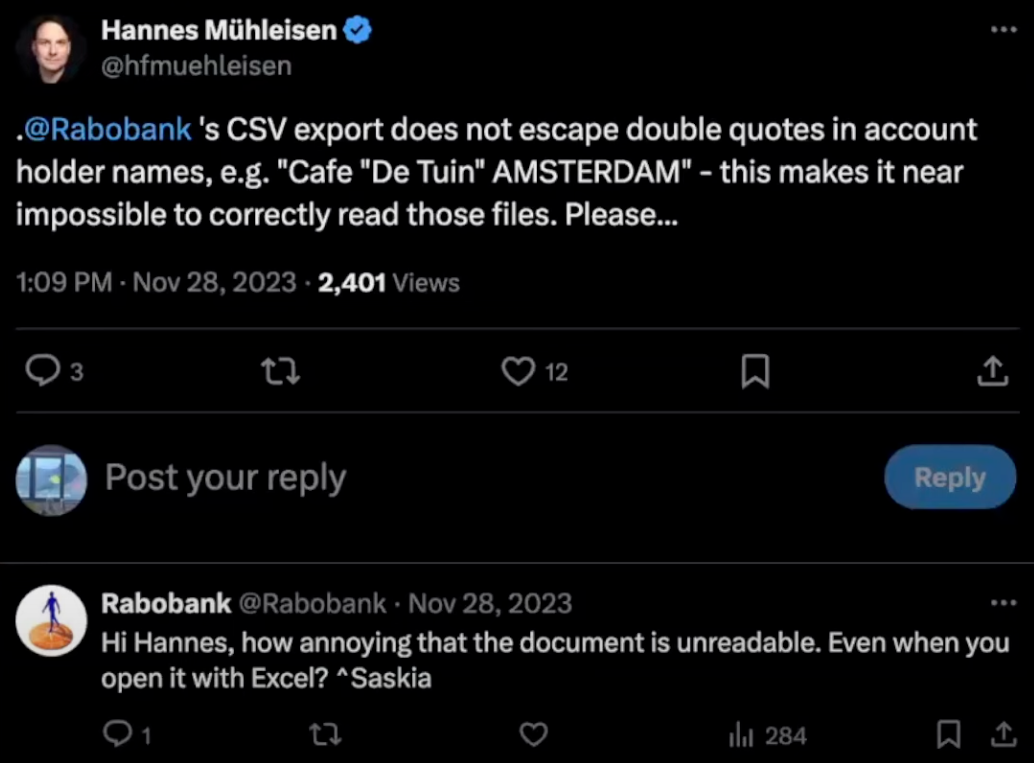
If a big financial institute cannot write proper CSV files, imagine the errors occurring in CSV files exported by decades-old legacy software, in hand-written CSV files, files exported from spreadsheet software, and so on! These sorts of errors are so prevalent that spreadsheet software, dataframe libraries and specialized CSV tools go above and beyond to salvage these files and hammer them into tables that users can work with.
DuckDB's CSV Parser
When we designed the DuckDB CSV parser, we strived to ensure that it's not only easy to use and fast, but also extremely reliable – to the point it can read most CSVs thrown at it. In this blog post, we study this from two angles. First, we explore the main options that can help you read non-standard CSV files and show their effects on parsing with some simple examples. Second, we evaluate how robust DuckDB's CSV parser is by putting it to the test with the Pollock Benchmark.
There is a lot of discourse on the internet about whether a system should go above and beyond to read files that do not follow the standard. And yes, non-standard files are frustrating. We can all complain about them on the internet or decide to ignore them. But we strongly believe that ignoring reality comes at a cost. Being able to read non-standard files – even if it might result in ambiguity – should be the user's decision.
Running Example
As our running example, we'll use a CSV file called cafes.csv:
ZIP,Name,Country
1014,"Cafe ""Gedoogt""",Netherlands
1015,"Cafe "De Tuin" Amsterdam",Netherlands
1095,Joost
1872,Cafe Gezellig,Netherlands,5
Despite its small size, the file contains many different errors. Let's inspect it line by line:
| Line | Row | Comment |
|---|---|---|
| 1 | ZIP,Name,Country |
The header of the file. |
| 2 | 1014,"Cafe ""Gedoogt""",Netherlands |
A well-defined line, with a quoted value that contains escaped quotes (""). |
| 3 | 1015,"Cafe "De Tuin" Amsterdam",Netherlands |
The value for Name contains unescaped quotes. |
| 4 | 1095,Joost |
This line is missing the value for the Country. |
| 5 | 1872,Cafe Gezellig,Netherlands,5 |
Has an extra column with the value 5. |
Loading the Example Naïvely
If we naïvely try to read our example, we get a table with only a single line:
FROM read_csv('cafes.csv');
┌─────────┬───────────────┬─────────────┬─────────┐
│ column0 │ column1 │ column2 │ column3 │
│ int64 │ varchar │ varchar │ int64 │
├─────────┼───────────────┼─────────────┼─────────┤
│ 1872 │ Cafe Gezellig │ Netherlands │ 5 │
└─────────┴───────────────┴─────────────┴─────────┘
We can see that the reader ignored all lines except the last one. Let's query the CSV sniffer to see the dialect it detected:
SELECT Delimiter, Quote, Escape, SkipRows
FROM sniff_csv('cafes.csv');
┌───────────┬─────────┬─────────┬──────────┐
│ Delimiter │ Quote │ Escape │ SkipRows │
│ varchar │ int16 │ varchar │ uint16 │
├───────────┼─────────┼─────────┼──────────┤
│ , │ \0 │ \0 │ 4 │
└───────────┴─────────┴─────────┴──────────┘
We can see that the sniffer decided that quotes and escape characters are not present in the file (represented as \0 values).
Consequently, it decided to skip the first 4 rows (including the header) in order to read the file according to the dialect.
Tip DuckDB allows users to retrieve all errors that occur when reading a CSV file using the
reject_errorstable. This is beyond the scope of this blog post, but you can find more details in the “Reading Faulty CSV Files” documentation page.
Loading the Example with a User-Defined CSV Dialect
Let's attempt to read the faulty CSV files with a user-defined CSV dialect.
To this end, we'll set the auto_detect option to false and manually specify the presence of the header, the values of the delim(iter), quote, and escape options, as well as the schema with the columns option.
FROM read_csv('cafes.csv',
auto_detect = false,
header = true,
delim = ',',
quote = '"',
escape = '"',
columns = {'ZIP': 'INT16', 'Name': 'VARCHAR', 'Country': 'VARCHAR'}
);
Running this SQL statement will result in an error due to unescaped quotes in line 3: the parser can't determine whether the first quote in "De Tuin" marks the end of the quoted value or not:
Invalid Input Error:
CSV Error on Line: 3
Original Line: 1015,"Cafe "De Tuin" Amsterdam",Netherlands
Value with unterminated quote found.
Possible fixes:
* Disable the parser's strict mode (strict_mode=false) to allow reading rows that do not comply with the CSV standard.
* Enable ignore errors (ignore_errors=true) to skip this row
* Set quote to empty or to a different value (e.g., quote='')
The error message informs us that there was a value with an unterminated quote, caused by the unescaped quote character. It also suggests some possible fixes, which will guide our attempts in the next sections.
Disabling Strict Mode
As the error message informed us, one of the ways to relax the constraints of the DuckDB CSV reader to read this file is by utilizing the strict_mode option. Namely, disabling the strict_mode option will allow the CSV Reader to go over the following common errors:
-
Unescaped quoted values, such as the one in line 3.
-
Rows that have too many columns. For example, for the row
1872,Cafe Gezellig,Netherlands,5, the last column is ignored to fit our schema of three columns. -
A mix of newline delimiters, e.g., files having both
\nand\r\nas newline delimiters. This error does not occur in our running example.
By default, strict_mode is set to true, which implies that DuckDB will not attempt to parse rows that do not fit the dialect.
However, setting it to false allows the CSV reader to attempt to read the file even if it cannot be correctly read under the given configuration.
Let's go back to our example and turn off strict mode:
FROM read_csv('cafes.csv',
auto_detect = false,
header = true,
strict_mode = false,
delim = ',',
quote = '"',
escape = '"',
columns = {'ZIP': 'INT16', 'Name': 'VARCHAR', 'Country': 'VARCHAR'}
);
We can see that the reader now only errors at line 4, indicating the previous lines were correctly read up to that point:
Invalid Input Error:
CSV Error on Line: 4
Original Line: 1095,Joost
Expected Number of Columns: 3 Found: 2
Possible fixes:
* Enable null padding (null_padding=true) to replace missing values with NULL
* Enable ignore errors (ignore_errors=true) to skip this row
It is important to note two things for the
strict_mode = falseoption:
When using this option, there is no guarantee that the result is correct. This is because it's impossible to define what constitutes a “correct result” when parsing a non-standard CSV file.
DuckDB runs a best-effort parser, as it will try only fail if it encounters an error to which it can't find any reasonable guess of what the correct data should look like (e.g., imagine a column of integers, where some integers are represented as a spelled-out string, this will cause a casting error). While it is possible that, with a given combination of errors, our parser may still fail, we are striving to make it even more robust as we face the abyss.
Ignoring Errors
The other option suggested by the error message was to set ignore_errors = true.
This option simply means that any rows which do not fit the chosen dialect or schema will be skipped from the result.
In practice, if we add it to our query:
FROM read_csv('cafes.csv',
auto_detect = false,
header = true,
strict_mode = false,
delim = ',',
quote = '"',
escape = '"',
columns = {'ZIP': 'INT16', 'Name': 'VARCHAR', 'Country': 'VARCHAR'},
ignore_errors = true
);
We get an almost complete result! Only missing line number 4 1095,Joost since it is missing a column.
┌───────┬────────────────────────┬─────────────┐
│ ZIP │ Name │ Country │
│ int16 │ varchar │ varchar │
├───────┼────────────────────────┼─────────────┤
│ 1014 │ Cafe "Gedoogt" │ Netherlands │
│ 1015 │ Cafe De Tuin Amsterdam │ Netherlands │
│ 1872 │ Cafe Gezellig │ Netherlands │
└───────┴────────────────────────┴─────────────┘
The
ignore_errorsoption also affects the sniffer's behavior, as it will ignore lines that produce errors during sniffing. In general, the configuration that results in the fewest errors will be preferred.
Null Padding for Missing Values
The last option that can help when reading non-standard CSV files is the null_padding option.
This option is useful when lines in the CSV file have an inconsistent number of values, with some missing values for given columns.
Let's read the file with the null_padding = true option.
FROM read_csv('cafes.csv',
auto_detect = false,
header = true,
strict_mode = false,
delim = ',',
quote = '"',
escape = '"',
columns = {'ZIP': 'INT16', 'Name': 'VARCHAR', 'Country': 'VARCHAR'},
null_padding = true
);
This will produce the following result:
┌───────┬────────────────────────┬─────────────┐
│ ZIP │ Name │ Country │
│ int16 │ varchar │ varchar │
├───────┼────────────────────────┼─────────────┤
│ 1014 │ Cafe "Gedoogt" │ Netherlands │
│ 1015 │ Cafe De Tuin Amsterdam │ Netherlands │
│ 1095 │ Joost │ NULL │
│ 1872 │ Cafe Gezellig │ Netherlands │
└───────┴────────────────────────┴─────────────┘
Minimal Configuration to Read the Example File
Whew. We loaded the file but the read_csv call is about 200 characters long!
Luckily, we can do better than that: if we set both strict_mode = false and null_padding = true, we only need to specify the quote and escape values.
This call only requires about 80 characters and gets a valid result from this CSV file:
FROM read_csv('cafes.csv',
strict_mode = false,
null_padding = true,
quote = '"',
escape = '"'
);
┌───────┬────────────────────────┬─────────────┬─────────┐
│ ZIP │ Name │ Country │ column3 │
│ int64 │ varchar │ varchar │ int64 │
├───────┼────────────────────────┼─────────────┼─────────┤
│ 1014 │ Cafe "Gedoogt" │ Netherlands │ NULL │
│ 1015 │ Cafe De Tuin Amsterdam │ Netherlands │ NULL │
│ 1095 │ Joost │ NULL │ NULL │
│ 1872 │ Cafe Gezellig │ Netherlands │ 5 │
└───────┴────────────────────────┴─────────────┴─────────┘
With this configuration, the sniffer actually creates a new column (column3) to accommodate the extra value in the last line.
This example shows that even on a CSV file exhibiting several issues, DuckDB's CSV sniffer can still make reasonably good decisions on the file's dialect and schema.
Tip You can drop the last column by e.g. using
SELECT #1, #2, #3 FROM ...in the query.
The Pollock Benchmark
The Pollock Benchmark is a CSV data loading benchmark designed to evaluate how robust a CSV system is when reading non-standard CSV files. The benchmark was published at VLDB 2023 and is completely open-source, with a DuckDB entry recently added to its repository.
The authors of the Pollock benchmark analyzed over 245,000 public CSV datasets to understand the most common ways the RFC-4180 standard is violated in CSV files in the wild. After identifying the most common error types, they created a CSV file generator with a pollution mechanism, which inserts these errors. In total, the benchmark tool generates over 2,200 polluted files. It also generates the correct dialect configuration that should be used to read these files, along with a clean version of the file.
To evaluate the robustness of systems, the benchmark tool reads the polluted file with the configuration set for a given system-under-test. It then uses the system to write a new file with the answer and compares it with the clean version. This comparison yields a score that reflects how accurately the system has read the file. There are mainly two scores that the benchmark produces: the simple score and the weighted score, with the weighted score accounting for how commonly that type of error appears in real life.
In this section, we will describe the most common errors depicted in the paper and share the results of the benchmark after adding DuckDB.
Common Errors
The paper depicts many of the common errors that appear in CSV files. In this section, we will briefly discuss some of the most common errors, but refer to the paper for a complete overview:
-
Inconsistent Number of Cells in Rows: RFC-4180 requires that all rows, including the header, have a consistent number of columns, but many files have too many or too few delimiters per row.
-
Non-Standard Newline Sequences: RFC-4180 requires that files use a carriage return followed by a line feed (
\r\n), but many files use only line feeds, carriage returns, or a mix of them. -
Multiple Header Lines: The standard allows for an optional single header line but many files have multiple headers.
-
Incorrectly Quoted or Unescaped Cells: This error occurs when quoted values have unescaped quotes in them. See the
file_escape_char_0x00.csvfor an example. Note how GitHub's table renderer, which can read the clean version of this file fails to parse it. -
Files with Multibyte Delimiters: The standard requires files to be comma-separated. Although single-byte delimiters are widely accepted, multibyte delimiters are common.
-
Files with Multiple Tables: When a CSV file stores multiple tables with different schemas in the same file.
Methodology
The benchmark includes a wide variety of systems being tested, such as CSV parsing frameworks (e.g., CleverCSV), relational database systems (e.g., PostgreSQL), spreadsheet software (e.g., LibreOffice Calc), data visualization tools (e.g., Dataviz), and dataframe libraries (e.g., Pandas).
An important aspect of the benchmark is that it provides the dialect and schema for each file. Without this, systems that do not have a sniffer (e.g., PostgreSQL) would not be able to read the file. There is no specific rule or differentiation in how much each system utilizes that information. For example, Pandas only takes partial advantage of these settings. To incorporate these differences in our evaluation of DuckDB, we decided to add two different configurations:
-
DuckDB (benchmark config). Under this configuration, all the options in the configuration file that are relevant to DuckDB – such as CSV dialect and schema – are passed to the reader. In addition, we also set all the options described in the previous section (i.e.,
null_padding = true, strict_mode = false, ignore_errors = true). This essentially tells us how much we can read from these files if the users manually set the necessary options. -
DuckDB (auto-detect only). Under this configuration, we do not take advantage of providing custom configuration files. The only options set are those that allow for non-standard file reading (i.e.,
null_padding = true, strict_mode = false, ignore_errors = true). Hence, this option also evaluates the full power of our sniffer in scenarios of uncertainty.
Pollock Scores
The following table presents the results with DuckDB included. We also limited the original table to show only the systems with the best scores in each category (e.g., parsing frameworks, relational systems, and so on). For both the simple and weighted scores, DuckDB with all options set (the default configuration for the Pollock benchmark) is the clear winner.
In terms of the simple score, this means that DuckDB correctly read 99.61% of the data from all the files.
It also correctly handles the most common errors, as reflected in the weighted score.
Pollock scores sorted by weighted score (out of 10):
| System under test | Pollock score (weighted) | Pollock score (simple) |
|---|---|---|
| DuckDB 1.2 (benchmark config) | 9.599 | 9.961 |
| “SpreadDesktop” | 9.597 | 9.929 |
| Pandas 1.4.3 | 9.431 | 9.895 |
| “SpreadWeb” | 9.431 | 9.721 |
| SQLite 3.39.0 | 9.375 | 9.955 |
| DuckDB 1.2 (auto-detect only) | 8.439 | 9.075 |
| UniVocity 2.9.1 | 7.936 | 9.939 |
| LibreOffice Calc 7.3.6 | 7.833 | 9.925 |
| Dataviz | 5.152 | 5.003 |
According to the benchmark's website, “SpreadDesktop” is a desktop-based commercial spreadsheet software and “SpreadWeb” is a web-based spreadsheet software. Their real names were omitted due to licensing.
Click here to see the full result table
| System under test | Pollock score (weighted) | Pollock score (simple) |
|---|---|---|
| DuckDB 1.2 (benchmark config) | 9.599 | 9.961 |
| “SpreadDesktop” | 9.597 | 9.929 |
| CleverCSV 0.7.4 | 9.453 | 9.193 |
| Python native csv 3.10.5 | 9.436 | 9.721 |
| Pandas 1.4.3 | 9.431 | 9.895 |
| “SpreadWeb” | 9.431 | 9.721 |
| SQLite 3.39.0 | 9.375 | 9.955 |
| CSVCommons 1.9.0 | 9.253 | 6.647 |
| DuckDB 1.2 (auto-detect only) | 8.439 | 9.075 |
| UniVocity 2.9.1 | 7.936 | 9.939 |
| LibreOffice Calc 7.3.6 | 7.833 | 9.925 |
| OpenCSV 5.6 | 7.746 | 6.632 |
| MySQL 8.0.31 | 7.484 | 9.587 |
| MariaDB 10.9.3 | 7.483 | 9.585 |
| PostgreSQL 15.0 | 6.961 | 0.136 |
| R native csv 4.2.1 | 6.405 | 7.792 |
| Dataviz | 5.152 | 5.003 |
| Hypoparsr 0.1.0 | 4.372 | 3.888 |
As expected, running DuckDB in full auto mode scores lower, since the sniffer must detect dialects and schemas by itself. Some files even have a multibyte delimiter, which is supported by DuckDB, but is not part of the sniffer's search space, yielding a lower score. In these cases, DuckDB still managed to read about 90.75% of the data correctly, reaching in 9.075 as the total score and 8.439 as the total weighted score.
Once again, this result comes from simply calling read_csv('file_path', null_padding = true, strict_mode = false, ignore_errors = true) with zero user input regarding the actual data configuration, demonstrating that DuckDB's CSV reader can indeed read most non-standard CSV files, even with minimal configuration!
Contributing to the Benchmark
It's entirely possible that your favorite CSV reader system is not yet included in the benchmark results. DuckDB, for example, was initially not included, but we found that adding it was quite easy! We hope that the DuckDB pull request serves as inspiration for those who wish to add their favorite systems to it. The reproduction of the results is quite simple too. Unlike most benchmarks that focus on performance and correctness, the Pollock Benchmark measures accuracy, making it easy to reproduce independently of the machine used.
Happy hacking!

