Friendly Lists and Their Buddies, the Lambdas
Introduction
Nested data types, such as lists and structs, are widespread in analytics. Several popular formats, such as Parquet and JSON, support nested types. Traditionally, working with nested types requires normalizing steps before any analysis. Then, to return nested results, systems need to (re-)aggregate their data. Normalization and aggregation are undesirable from both a usability and performance perspective. To streamline the operation on nested data, analytical systems, including DuckDB, provide native functionality on these nested types.
In this blog post, we'll first cover the basics of lists and lambdas. Then, we dive into their technical details. Finally, we'll show some examples from the community. Feel free to skip ahead if you're already familiar with lists and lambdas and are just here for our out-of-the-box examples!
Lists
Before jumping into lambdas, let's take a quick detour into DuckDB's LIST type.
A list contains any number of elements with the same data type.
Below is a table containing two columns, l and n.
l contains lists of integers, and n contains integers.
CREATE OR REPLACE TABLE my_lists (l INTEGER[], n INTEGER);
INSERT INTO my_lists VALUES ([1], 1), ([1, 2, 3], 2), ([-1, NULL, 2], 2);
FROM my_lists;
┌───────────────┬───────┐
│ l │ n │
│ int32[] │ int32 │
├───────────────┼───────┤
│ [1] │ 1 │
│ [1, 2, 3] │ 2 │
│ [-1, NULL, 2] │ 2 │
└───────────────┴───────┘
Internally, all data moves through DuckDB's execution engine in Vectors.
For more details on Vectors and vectorized execution, please refer to the documentation and respective research papers (1 and 2).
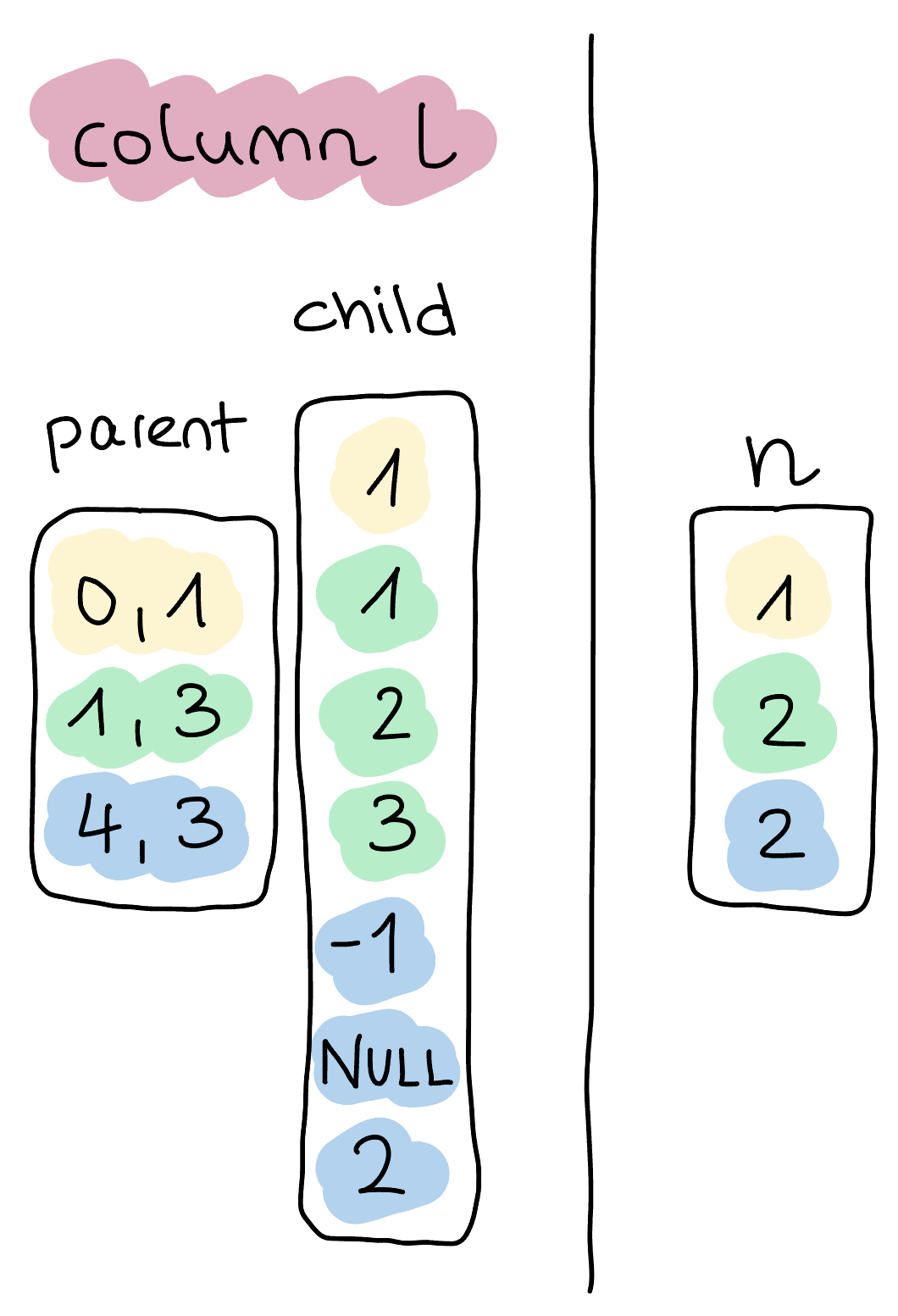
In this case, we get two vectors, as depicted below.
This representation is mostly similar to Arrow's physical list representation.
When examined closely, we can observe that the nested child vector of l looks suspiciously similar to the vector n.
These nested vector representations enable our execution engine to reuse existing components on nested types.
We'll elaborate more on why this is relevant later.
Lambdas
A lambda function is an anonymous function, i.e., a function without a name.
In DuckDB, a lambda function's syntax is lambda param1, param2, ...: expression.
The parameters can have any name, and the expression can be any SQL expression.
Currently, DuckDB has three scalar functions for working with lambdas:
list_transform,
list_filter,
and
list_reduce,
along with their aliases.
Each accepts a LIST as its first argument and a lambda function as its second argument.
Lambdas were the guest star in our SQL Gymnastics: Bending SQL into Flexible New Shapes blog post. This time, we want to put them in the spotlight.
Zooming In: List Transformations
To return to our previous example, let's say we want to add n to each element of the corresponding list l.
Pure Relational Solution
Using pure relational operators, i.e., avoiding list-native functions, we would need to perform the following steps:
- Unnest the lists while keeping the connection to their respective rows.
We can achieve this by inventing a temporary unique identifier, such as a
rowidor aUUID. - Transform each element by adding
n. - Using our temporary identifier
rowid, we can reaggregate the transformed elements by grouping them into lists.
In SQL, it would look like this:
WITH flattened_tbl AS (
SELECT unnest(l) AS elements, n, rowid
FROM my_lists
)
SELECT array_agg(elements + n) AS result
FROM flattened_tbl
GROUP BY rowid
ORDER BY rowid;
┌──────────────┐
│ result │
│ int32[] │
├──────────────┤
│ [2] │
│ [3, 4, 5] │
│ [1, NULL, 4] │
└──────────────┘
While the above example is reasonably readable, more complex transformations can become lengthy queries, which are difficult to compose and maintain.
More importantly, this query adds an unnest operation and an aggregation (array_agg) with a GROUP BY.
Adding a GROUP BY can be costly, especially for large datasets.
We have to dive into the technical implications to fully understand why the above query yields suboptimal performance.
Internally, the query execution performs the steps depicted in the diagram below.
We can directly emit the child vector for the unnest operation, i.e., without copying any data.
For the correlated columns rowid and n, we use selection vectors, which again prevents the copying of data.
This way, we can fire our expression execution on the child vector, another nested vector, and the expanded vector n.
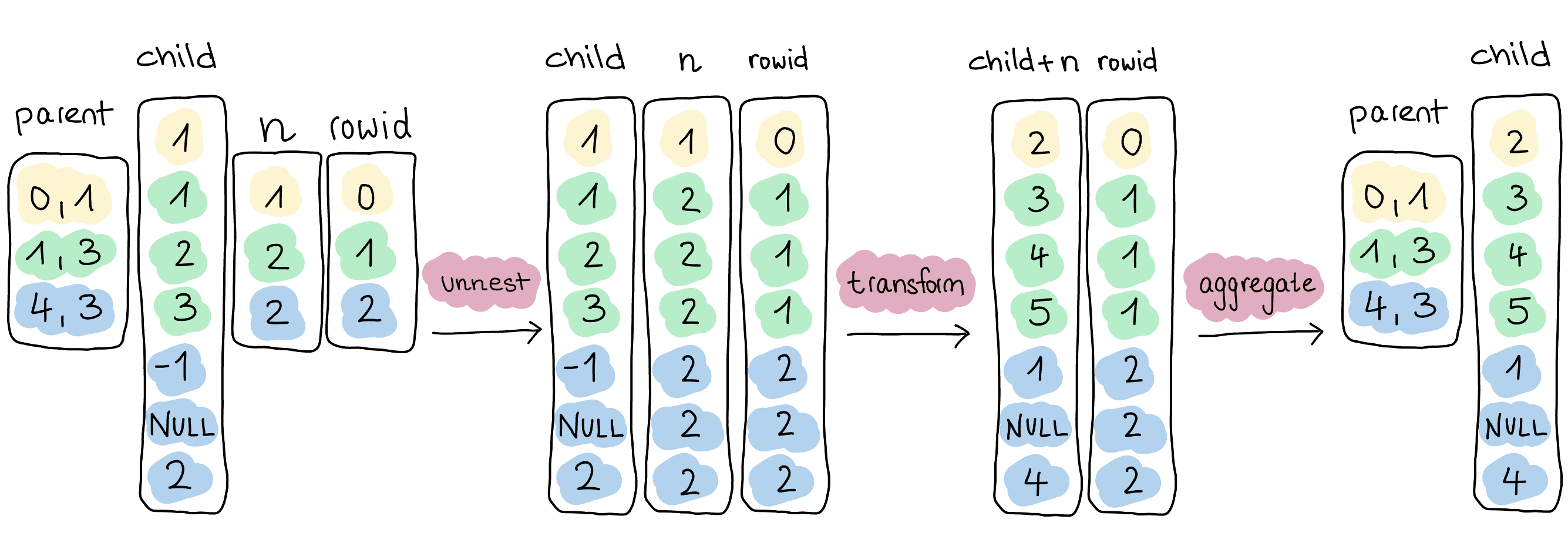
The heavy-hitting operation is the last one, reaggregating the transformed elements into their respective lists. As we don't propagate the parent vector, we have no information about the resulting element's correlation to the initial lists. Recreating these lists requires a full copy of the data and partitioning, which impacts performance even with DuckDB's high-performance aggregation operator.
As a consequence, the normalized approach is both cumbersome to write and it is inefficient as it produces a significant (and unnecessary) overhead despite the relative simplicity of the query. This is yet another example of how shaping nested data into relational forms or forcing it through rectangles can have a significant negative performance impact.
Native List Functions
With support for native list functions, DuckDB mitigates these drawbacks by operating directly on the LIST data structure.
Since, as we've seen, lists are essentially nested columns, we can reshape these functions into concepts already understood by our execution engine and leverage their full potential.
In the case of transformations, the corresponding list-native function is list_transform.
Here is the rewritten query:
SELECT list_transform(l, lambda x: x + n) AS result
FROM my_lists;
Alternatively, with Python's list comprehension syntax:
SELECT [x + n FOR x IN l] AS result
FROM my_lists;
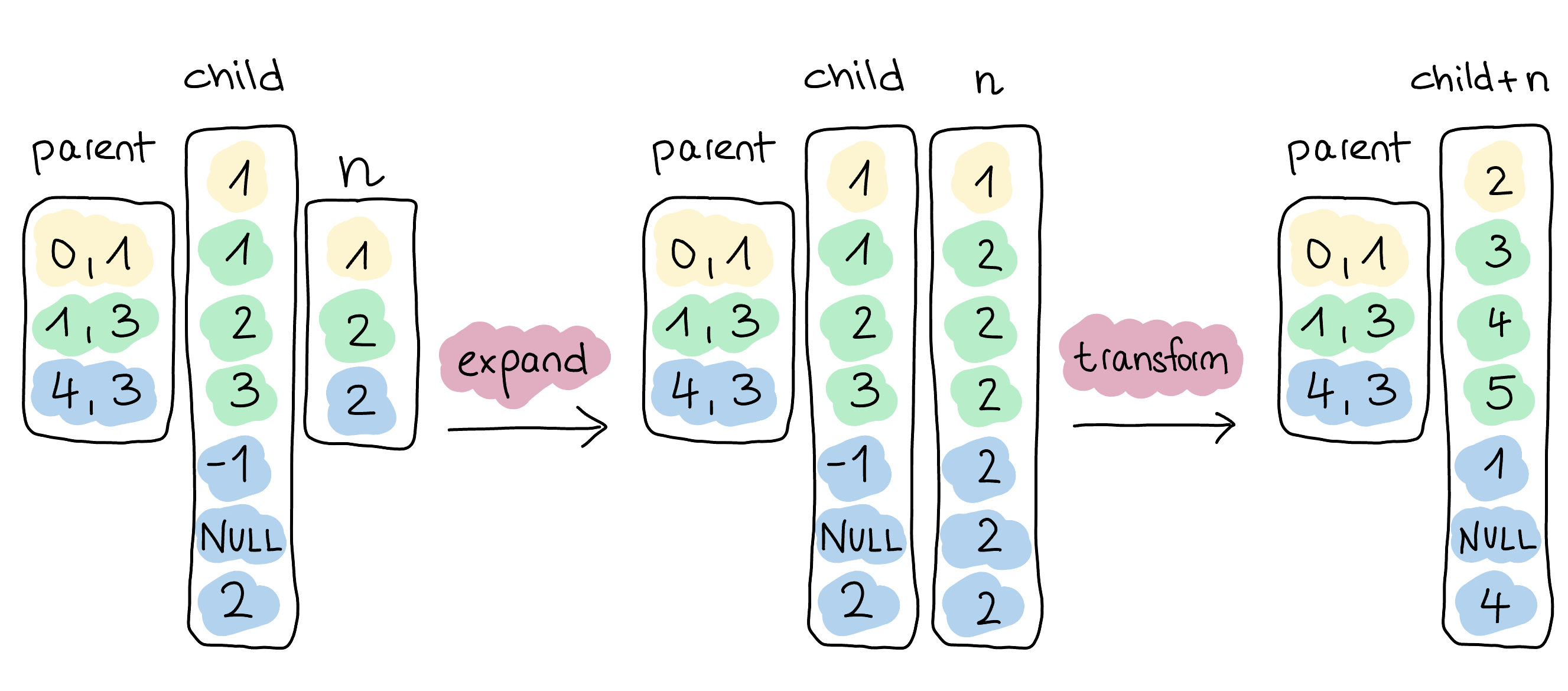
Internally, this query expands all related vectors, which is just n in this case.
Just like before, we employ selection vectors to avoid any data copies.
Then, we use the lambda function x: x + n to fire our expression execution on the child vector and the expanded vector n.
As this is a list-native function, we’re aware of the existence of a parent vector and keep it alive.
So, once we get the result from the transformation, we can completely omit the reaggregation step.
To see the efficiency of list_transform in action, we executed a simple benchmark.
Firstly, we added 1M rows to our table my_lists, each containing five elements.
INSERT INTO my_lists
SELECT [r, r % 10, r + 5, r + 11, r % 2], r
FROM range(1_000_000) AS tbl(r);
Then, we ran both our normalized and list-native queries on this data. Both queries were run in the CLI with DuckDB v1.0.0 on a MacBook Pro 2021 with a M1 Max chip.
| Normalized | Native |
|---|---|
| 0.522 s | 0.027 s |
As we can see, the native query is more than 10× faster. Amazing!
If we look at the execution plan using EXPLAIN ANALYZE (not shown in this blog post), we can see that DuckDB spends most of its time in the HASH_GROUP_BY and UNNEST operators.
In comparison, these operators no longer exist in the list-native query plan.
Lists and Lambdas in the Community
To better present what's possible by combining our LIST type and lambda functions, we've scoured the community Discord and GitHub, as well as some far corners of the internet, for exciting use cases.
list_transform
As established earlier, list_transform applies a lambda function to each element of the input list and returns a new list with the transformed elements.
Here, one of our users implemented a list_shuffle function by nesting different LIST native functions.
CREATE OR REPLACE MACRO list_shuffle(l) AS (
list_select(l, list_grade_up([random() FOR _ IN l]))
);
Another user investigated querying remote Parquet files using DuckDB.
In their query, they first use list_transform to generate a list of URLs for Parquet files.
This is followed by the read_parquet function, which reads the Parquet files and calculates the total size of the data.
The query looks like this:
SELECT
sum(size) AS size
FROM read_parquet(
['https://huggingface.co/datasets/vivym/midjourney-messages/resolve/main/data/' ||
format('{:06d}', n) || '.parquet'
FOR n IN generate_series(0, 55)
]
);
list_filter
The list_filter function filters all elements of the input list for which the lambda function returns true.
Here is an example using list_filter from a discussion on our Discord where the user wanted to remove the element at index idx from each list.
CREATE OR REPLACE MACRO remove_idx(l, idx) AS (
list_filter(l, lambda _, i: i != idx)
);
So far, we've primarily focused on showcasing our lambda function support in this blog post.
Yet, there are often many possible paths with SQL and its rich dialects.
We couldn't help but show how we can achieve the same functionality with some of our other native list functions.
In this case, we used list_slice and list_concat.
CREATE OR REPLACE MACRO remove_idx(l, idx) AS (
l[:idx - 1] || l[idx + 1:]
);
list_reduce
Most recently, we've added list_reduce, which applies a lambda function to an accumulator value.
The accumulator is the result of the previous lambda function and is also what the function ultimately returns.
We took the following example from a discussion on GitHub. The user wanted to use a lambda to validate BSN numbers, the Dutch equivalent of social security numbers. A BSN must be 8 or 9 digits, but to limit our scope we'll just focus on BSNs that are 9 digits long. After multiplying each digit by its index, from 9 down to 2, and the last digit by -1, the sum must be divisible by 11 to be valid.
Setup
For our example, we assume that input BSNs are of type INTEGER[].
CREATE OR REPLACE TABLE bsn_tbl AS
FROM VALUES
([2, 4, 6, 7, 4, 7, 5, 9, 6]),
([1, 2, 3, 4, 5, 6, 7, 8, 9]),
([7, 6, 7, 4, 4, 5, 2, 1, 1]),
([8, 7, 9, 0, 2, 3, 4, 1, 7]),
([1, 2, 3, 4, 5, 6, 7, 8, 9, 0])
tbl(bsn);
Solution
CREATE OR REPLACE MACRO valid_bsn(bsn) AS (
bsn.list_reverse().list_reduce(
lambda x, y, i: IF (i = 2, -x, x) + y * i
) % 11 = 0
AND len(bsn) = 9
);
Using our macro with the example table we get the following result:
SELECT bsn, valid_bsn(bsn) AS valid
FROM bsn_tbl;
┌────────────────────────────────┬─────────┐
│ bsn │ valid │
│ int32[] │ boolean │
├────────────────────────────────┼─────────┤
│ [2, 4, 6, 7, 4, 7, 5, 9, 6] │ true │
│ [1, 2, 3, 4, 5, 6, 7, 8, 9] │ false │
│ [7, 6, 7, 4, 4, 5, 2, 1, 1] │ true │
│ [8, 7, 9, 0, 2, 3, 4, 1, 7] │ true │
│ [1, 2, 3, 4, 5, 6, 7, 8, 9, 0] │ false │
└────────────────────────────────┴─────────┘
Conclusion
Native nested type support is critical for analytical systems.
As such, DuckDB offers native nested type support and many functions to work with these types directly.
These functions make working with nested types easier and substantially faster.
In this blog post, we looked at the technical details of working with nested types by diving into our list_transform function.
Additionally, we highlighted various use cases that we came across in our community.

