DuckDB: Running TPC-H SF100 on Mobile Phones
TL;DR: DuckDB runs on mobile platforms such as iOS and Android, and completes the TPC-H benchmark faster than state-of-the-art research systems on big iron machines 20 years ago.
A few weeks ago, we set out to perform a series of experiments to answer two simple questions:
- Can DuckDB complete the TPC-H queries on the SF100 data set when running on a new smartphone?
- If so, can DuckDB complete a run in less than 400 seconds, i.e., faster than the system in the research paper that originally introduced vectorized query processing?
These questions took us on an interesting quest. Along the way, we had a lot of fun and learned the difference between a cold run and a really cold run. Read on to find out more.
A Song of Dry Ice and Fire
Our first attempt was to use an iPhone, namely an iPhone 16 Pro. This phone has 8 GB memory and a 6-core CPU with 2 performance cores (running at 4.05 GHz) and 4 efficiency cores (running at 2.42 GHz).
We implemented the application using the DuckDB Swift client and loaded the benchmark on the phone, all 30 GB of it. We quickly found that the iPhone can indeed run the workload without any problems – except that it heated up during the workload. This prompted the phone to perform thermal throttling, slowing down the CPU to reduce heat production. Due to this, DuckDB took 615.1 seconds. Not bad but not enough to reach our goal.
The results got us thinking: what if we improve the cooling of the phone? To this end, we purchased a box of dry ice, which has a temperature below -50 degrees Celsius, and put the phone in the box for the duration of the experiments.

This helped a lot: DuckDB completed in 478.2 seconds. This is a more than 20% improvement – but we still didn't manage to be under 400 seconds.

Do Androids Dream of Electric Ducks?
In our next experiment, we picked up a Samsung Galaxy S24 Ultra phone, which runs Android 14. This phone is full of interesting hardware. First, it has an 8-core CPU with 4 different core types (1×3.39 GHz, 3×3.10 GHz, 2×2.90 GHz and 2×2.20 GHz). Second, it has a huge amount of RAM – 12 GB to be precise. Finally, its cooling system includes a vapor chamber for improved heat dissipation.
We ran DuckDB in the Termux terminal emulator. We compiled DuckDB CLI client from source following the Android build instructions and ran the experiments from the command line.
In the end, it wasn't even close. The Android phone completed the benchmark in 235.0 seconds, outperforming our baseline by around 40%.
Never Was a Cloudy Day
The results got us thinking: how do the results stack up among cloud servers? We picked two x86-based cloud instances in AWS EC2 with instance-attached NVMe storage.
The details of these benchmarks are far less interesting than those of the previous ones. We booted up the instances with Ubuntu 24.04 and ran DuckDB in the command line. We found that an r6id.large instance (2 vCPUs with 16 GB RAM) completes the queries in 570.8 seconds, which is roughly on-par with an air-cooled iPhone. However, an r6id.xlarge (4 vCPUs with 32 GB RAM) completes the benchmark in 166.2 seconds, faster than any result we achieved on phones.
Summary of DuckDB Results
The table contains a summary of the DuckDB benchmark results.
| Setup | CPU cores | Memory | Runtime |
|---|---|---|---|
| iPhone 16 Pro (air-cooled) | 6 | 8 GB | 615.1 s |
| iPhone 16 Pro (dry ice-cooled) | 6 | 8 GB | 478.2 s |
| Samsung Galaxy S24 Ultra | 8 | 12 GB | 235.0 s |
AWS EC2 r6id.large |
2 | 16 GB | 570.8 s |
AWS EC2 r6id.xlarge |
4 | 32 GB | 166.2 s |
Historical Context
So why did we set out to run these experiments in the first place?
Just a few weeks ago, CWI, the birthplace of DuckDB, held a ceremony for the Dijkstra Fellowship. The fellowship was awarded to Marcin Żukowski for his pioneering role in the development of database management systems and his successful entrepreneurial career that resulted in systems such as VectorWise and Snowflake.
A lot of ideas that originate in Marcin's research are used in DuckDB. Most importantly, vectorized query processing allows DuckDB to be both fast and portable at the same time. With his co-authors Peter Boncz and Niels Nes, he first described this paradigm in the CIDR 2005 paper “MonetDB/X100: Hyper-Pipelining Query Execution”.
The terms vectorization, hyper-pipelining, and superscalar refer to the same idea: processing data in slices, which turns out to be a good compromise between row-at-a-time or column-at-a-time. DuckDB's query engine uses the same principle.
This paper was published in January 2005, so it's safe to assume that it was finalized in late 2004 – almost exactly 20 years ago!
If we read the paper, we learn that the experiments were carried out on an HP workstation equipped with 12 GB of memory (the same amount as the Samsung phone has today!). It also had an Itanium CPU and looked like this:

Upon its release in 2001, the Itanium was aimed at the high-end market with the goal of eventually replacing the then-dominant x86 architecture with a new instruction set that focused heavily on SIMD (single instruction, multiple data). While this ambition did not work out, the Itanium was the state-of-the-art architecture of its day. Due to the focus on the server market, the Itanium CPUs had a large amount of cache: the 1.3 GHz Itanium2 model used in the experiments had 3 MB of L2 cache, while Pentium 4 CPUs released around that time only had 0.5–1 MB.
The paper provides a detailed breakdown of the runtimes:
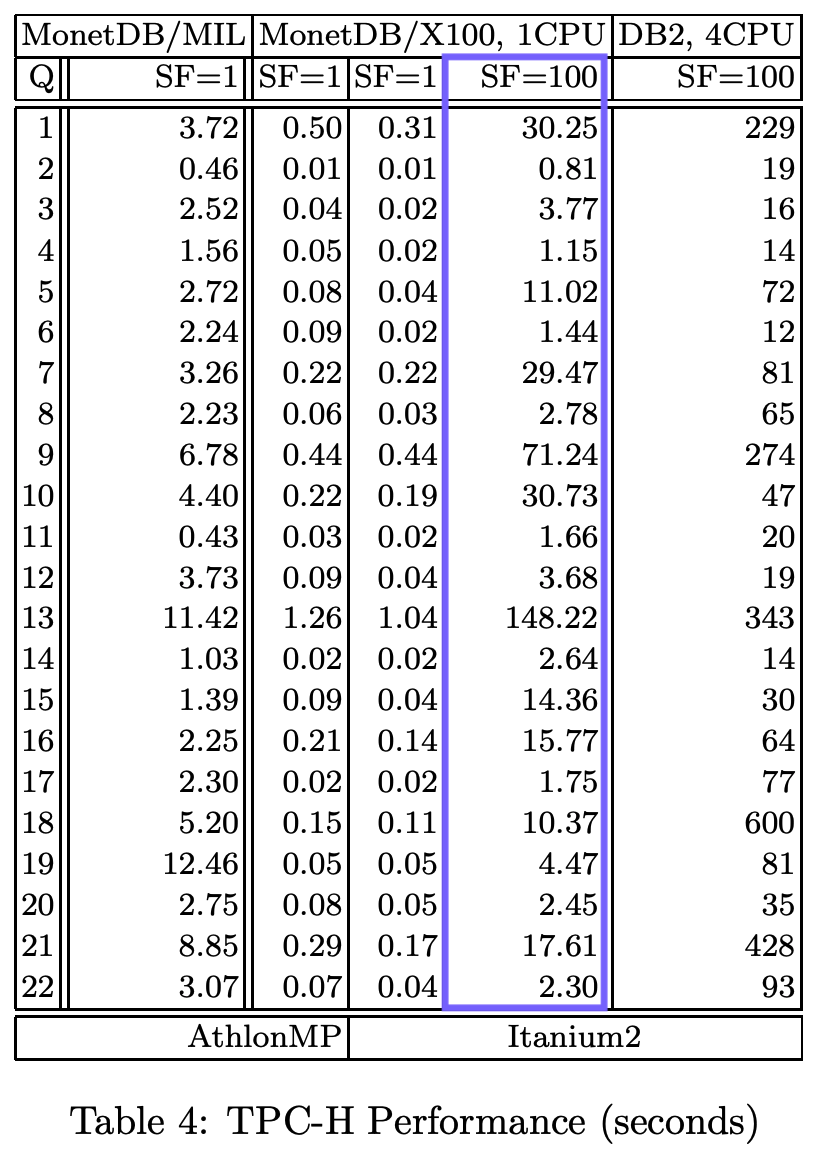
The total runtime of the TPC-H SF100 queries was 407.9 seconds – hence our baseline for the experiments. Here is a video of Hannes presenting the results at the event:
And here are all results visualized on a plot:

Conclusion
It was a long journey from the original vectorized execution paper to running an analytical database on a phone. Many key innovations happened that allowed these results, and the big improvement in hardware is just one of them. Another crucial component is that compiler optimizations became a lot more sophisticated. Thanks to this, while the MonetDB/X100 system needed to use explicit SIMD, DuckDB can rely on the auto-vectorization of our (carefully constructed) loops.
All that's left is to answer questions that we posed at the beginning of our journey. Yes, DuckDB can run TPC-H SF100 on a mobile phone. And yes, in some cases it can even outperform a research prototype running on a high-end machine of 2004 – on a modern smartphone that fits in your pocket.
And with newer hardware, smarter compilers and yet-to-be-discovered database optimizations, future versions are only going to be faster.


{kind=link}