Native Delta Lake Support in DuckDB

TL;DR: DuckDB now has native support for Delta Lake, an open-source lakehouse framework, with the delta extension.
Over the past few months, DuckLabs has teamed up with Databricks to add first-party support for Delta Lake in DuckDB using
the new delta-kernel-rs project. In this blog post we'll give you a short
overview of Delta Lake, Delta Kernel and, of course, present the new DuckDB Delta extension.
If you're already dearly familiar with Delta Lake and Delta Kernel, or you are just here to know how to boogie, feel free to skip to the juicy bits on how to use the DuckDB with Delta.
Intro
Delta Lake is an open-source storage framework that enables building a lakehouse architecture. So to understand Delta Lake, we need to understand what the lakehouse architecture is. The lakehouse is a data management architecture that strives to combine the cost-effectiveness of cheap object storage with a smart management layer. In simple terms, lakehouse architectures are a collection of files in various formats, with some additional metadata layers on top. These metadata layers aim to provide extra functionality on top of the raw collection of files such as ACID transactions, time travel, partition- and schema evolution, statistics, and much more. What a lakehouse architecture enables, is to run various types of data-intensive applications such as data analytics and machine learning applications, directly on a vast collection of structured, semi-structured and unstructured data, without the need for an intermediate data warehousing step. If you're ready for the deep dive, we recommend reading the CIDR 2021 paper "Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics" by Michael Armbrust et al. However, if you're (understandably) hesitant to dive into dense scientific literature, this image sums it up pretty well:
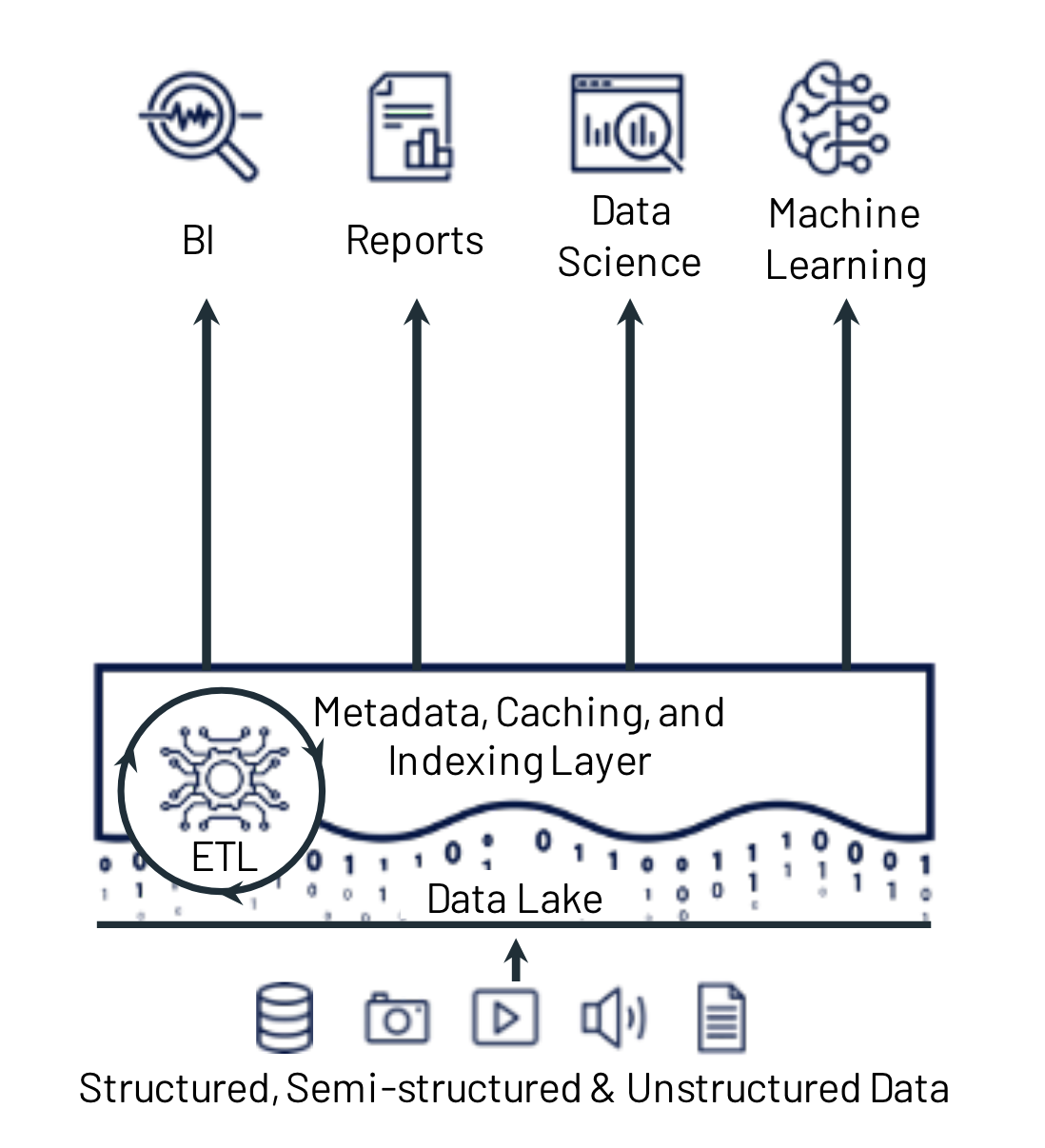
Delta Lake
Now let’s zoom in a little on our star of the show for tonight, Delta Lake. Delta Lake (or simply "Delta") is currently one of the leading open-source
lakehouse formats, along with Apache Iceberg and Apache Hudi. The easiest way to get a feeling for what a Delta table is, is to think of
a Delta table as a "collection of Parquet files with some metadata". With this slight oversimplification in mind, we will now create a
Delta table and examine the files that are created, to improve our understanding. To do this, we'll set up Python with the packages: duckdb, pandas and deltalake:
pip install duckdb pandas deltalake
Then, we use DuckDB to create some dataframes with test data, and write that to a Delta table using the deltalake package:
import duckdb
from deltalake import DeltaTable, write_deltalake
con = duckdb.connect()
df1 = con.query("SELECT i AS id, i % 2 AS part, 'value-' || i AS value FROM range(0, 5) tbl(i)").df()
df2 = con.query("SELECT i AS id, i % 2 AS part, 'value-' || i AS value FROM range(5, 10) tbl(i)").df()
write_deltalake(f"./my_delta_table", df1, partition_by=["part"])
write_deltalake(f"./my_delta_table", df2, partition_by=["part"], mode='append')
With this script run, we have created a basic Delta table containing 10 rows, split across two partitions that we added in two separate steps. To double-check that everything is going to plan, let’s use DuckDB to query the table:
SELECT *
FROM delta_scan('./my_delta_table')
ORDER BY id;
| id | part | value |
|---|---|---|
| 0 | 0 | value-0 |
| 1 | 1 | value-1 |
| 2 | 0 | value-2 |
| 3 | 1 | value-3 |
| 4 | 0 | value-4 |
| 5 | 1 | value-5 |
| 6 | 0 | value-6 |
| 7 | 1 | value-7 |
| 8 | 0 | value-8 |
| 9 | 1 | value-9 |
That looks great! All our expected data is there. Now let’s take a look at what files have actually been created using tree:
tree ./my_delta_table`
my_delta_table
├── _delta_log
│ ├── 00000000000000000000.json
│ └── 00000000000000000001.json
├── part=0
│ ├── 0-f45132f6-2231-4dbd-aabb-1af29bf8724a-0.parquet
│ └── 1-76c82535-d1e7-4c2f-b700-669019d94a0a-0.parquet
└── part=1
├── 0-f45132f6-2231-4dbd-aabb-1af29bf8724a-0.parquet
└── 1-76c82535-d1e7-4c2f-b700-669019d94a0a-0.parquet
The tree output shows 2 different types of files. While a Delta table can contain various other types of files, these form
the basis of any Delta table.
Firstly, there are data files in Parquet format. The data files contain all the data that is stored in the table. This is very similar to how data is stored when DuckDB is used to write partitioned Parquet files.
Secondly, there are delta files in JSON format. The Delta files contain a log of the changes that have been made to the table. By replaying this log, a reader can construct a valid view of the table. To illustrate this, let’s take a small peek into one of the first Delta log files:
cat my_delta_table/_delta_log/00000000000000000000.json
...
{ "add": {
"path": "part=1/0-f45132f6-2231-4dbd-aabb-1af29bf8724a-0.parquet",
"partitionValues": { "part": "1" }
},
...
}
{ "add": {
"path": "part=0/0-f45132f6-2231-4dbd-aabb-1af29bf8724a-0.parquet",
"partitionValues": { "part": "0" },
},
...
}
...
As we can see, this log file contains two add objects that describe some data being added to respectively the 1 and 0 partitions. Note also
that the partition values themselves are stored in these Delta files explicitly, so even though the file structure looks very similar
to a Hive-style partitioning scheme, the folder names are not actually used by Delta internally. Instead, the partition values are read from the metadata.
Now with this simple example, we've shown the basics of how Delta works. For a more thorough understanding of the internals, we refer to the official Delta specification, which is, by protocol specification standards, quite easy to read. The official specification describes in detail how Delta handles every detail, from the basics described here to more complex things like checkpointing, deletes, schema evolution, and much more.
Implementation
The Delta Kernel
Supporting a relatively complex protocol such as Delta, requires significant development and maintenance effort. For this reason, when looking to
add support for such a protocol to an engine, the logical choice would be to look for a ready-to-use library to take care of this. In the case of Delta Lake, we could, for example, opt for the delta-rs library.
However, when it comes to implementing a native DuckDB Delta extension, this is problematic:
if we were to use the delta-rs library for implementing the DuckDB extension, all interaction with the Delta tables would go through the delta-rs library. But remember,
a Delta table is effectively "just a bunch of Parquet files with some metadata". Therefore, this would mean that when DuckDB wants to read a Delta table,
the data files will be read by the delta-rs Parquet reader, using thedelta-rs filesystem. But that's annoying: DuckDB already comes shipped with
an excellent Parquet reader. Also, DuckDB already has support for a variety of filesystems with its own credential management system. By using a library like
delta-rs for DuckDB's Delta extension this would actually run into a variety of problems:
- increased extension binary size
- inconsistent user experience between
delta_scanandread_parquet - increased maintenance load
Now to solve these problems, we would prefer to have some library that implements only the Delta protocol while letting DuckDB handle all the things it already knows how to handle.
Fortunately for us, this library exists and it's called the Delta Kernel Project. The Delta Kernel is a "set of libraries for building Delta connectors that can read from and write into Delta tables without the need to understand the Delta protocol details". This is done by exposing two relatively simple sets of APIs that an engine would implement, as shown in the image below:
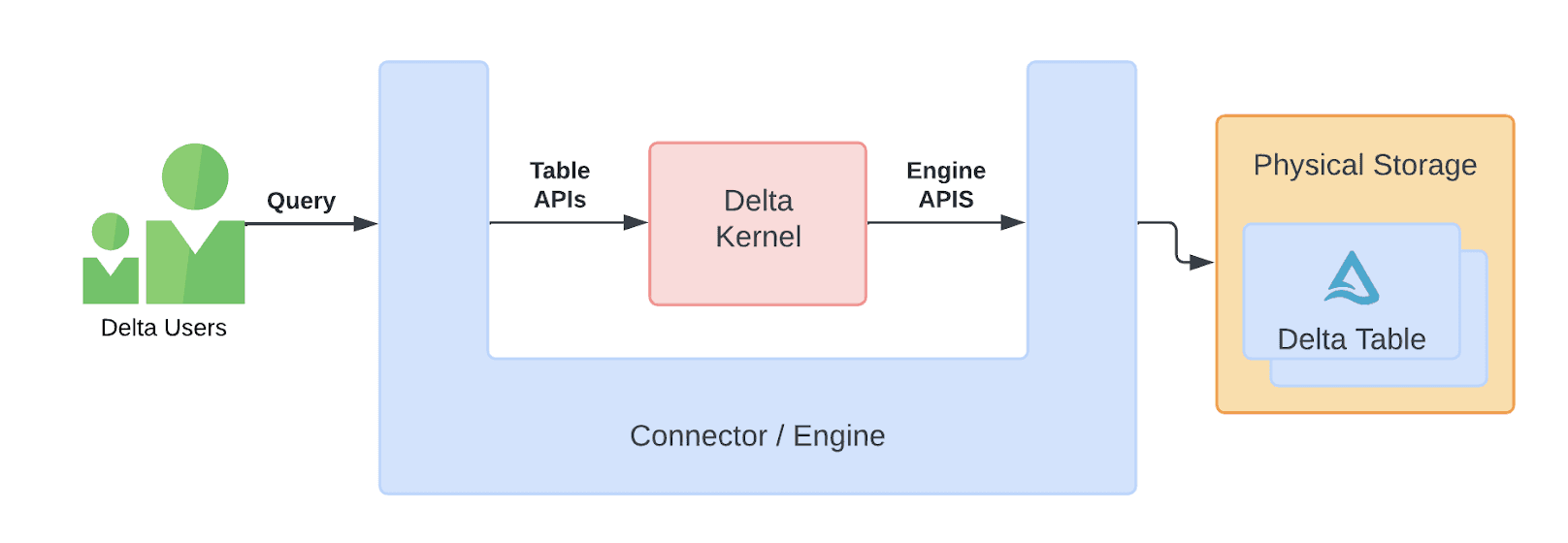
For more details on the delta-kernel-rs project, we refer to this excellent blog post, which goes in-depth into
the internals and design rationale.
Now while the delta-kernel-rs library is still experimental, it has recently launched its v0.1.0 version, and already offers a lot of functionality.
Furthermore, because delta-kernel-rs exposes a C/C++ foreign function interface, integrating it into a DuckDB extension has been very straightforward.
DuckDB Delta Extension delta_scan
Now we're ready to dive into the nitty-gritties of the DuckDB Delta extension internals. To start, the Delta extension
currently implements a single table function: delta_scan. It's a simple but powerful function that scans a Delta Table.
To understand how this function is implemented, we first need to establish the four main components involved:
| Component | Description |
|---|---|
| Delta kernel | The delta-kernel-rs library |
| Delta extension | DuckDB's loadable Delta extension |
| Parquet extension | DuckDB's loadable Parquet extension |
| DuckDB | Super cool duck-themed analytical database |
Additionally, we need to understand that there are four main APIs involved:
| API | Description |
|---|---|
FileSystem |
DuckDB's API for I/O (for local files, Azure, S3, etc.) |
TableFunction |
DuckDB's API for table functions (e.g., read_parquet, read_csv) |
MultiFileReader |
DuckDB's API for handling multi-file scans |
| Delta Kernel C/C++ FFI | Delta Kernel FFI for Delta Lake |
Now we have all the links, let's tie them all together. When a user runs a query with a delta_scan table function,
DuckDB will call into the delta_scan function from the Delta extension using the TableFunction API. The delta_scan table function, however,
is actually just an exact copy of the regular read_parquet function.
To change the read_parquet into a delta_scan, it will replace the regular MultiFileReader of the parquet_scan (which simply scans a list or glob of files), with
a custom DeltaMultiFileReader that will generate a list of files based on the Delta Table metadata. Finally, whenever the Parquet extension requires
any IO, it will call into DuckDB using the FileSystem API to handle the I/O. This entire interaction is captured in the diagram below.


In this Diagram, we can see all four components involved in the processing of query containing a delta_scan table function. The arrows represent the communication that occurs
between the components across the four APIs. Now when reading a Delta Table, we can see that the Metadata is handled on the right side going through the Delta Kernel. On the left side
we can see how the Parquet data flows through the Parquet extension.
While there are obviously some important details missing here, such as the handling of deletion vectors and column mappings, we have now covered the basic concept of the DuckDB Delta extension. Also, we have demonstrated how the current implementation achieves a very natural logical separation, with component internals being abstracted away by connecting through clearly defined APIs. In doing so, the implementation achieves the following key properties:
-
The details of the Delta protocol remain largely opaque to any DuckDB component. The only point of contact with the internals of the Delta protocol is the narrow FFI exposed by the Delta kernel. This is fully handled by the Delta extension, whose only job is to translate this into native DuckDB APIs.
-
Full reuse of existing Parquet scanning logic of DuckDB, without any code reuse or compile time dependencies between extensions. Because all interaction between the Delta and Parquet extension is done over DuckDB APIs through the running DuckDB instance, the extensions only interface over the
TableFunctionandMultiFileReaderAPIs. This also means that any future optimizations that are made to the Parquet extension will automatically be available in the Delta extension. -
All I/O will go through DuckDB's
FileSystemAPI. This means that all file systems (Azure, S3, etc.) that are available to DuckDB, are available to scan with. This means that any DuckDB file system that can read and list files can be used for Delta. This is also useful in DuckDB-Wasm where custom filesystem implementations are used. Warning, two small notes need to be made here. Firstly, currently the DuckDB Delta extension still lets a small part of IO be handled by the Delta kernel through internal filesystem libraries, this is due to the FFI not yet exposing theFileSystemAPIs, but this will change very soon. Secondly, while the architectural design of the Delta Extension is made with DuckDB-Wasm in mind, the Wasm version of the extension is not yet available.
How to Use Delta in DuckDB
Using the Delta extension in DuckDB is very simple, as it is distributed as one of the core DuckDB extensions, and available for autoloading. What this means is that you can simply start DuckDB (using v0.10.3 or higher) and run:
SELECT * FROM delta_scan('./my_delta_table');
DuckDB will automatically install and load the Delta Extension. Then it will query the local Delta table ./my_delta_table.
In case your Delta table lives on S3, there are probably some S3 credentials that you want to set. If these credentials are already in
one of the default places, such as an environment variable, or in the ~/.aws/credentials file? Simply run:
CREATE SECRET delta_s1 (
TYPE s3,
PROVIDER credential_chain
)
SELECT * FROM delta_scan('s3://some-bucket/path/to/a/delta/table');
Do you prefer remembering your AWS tokens by heart, and would like to type them out? Go with:
CREATE SECRET delta_s2 (
TYPE s3,
KEY_ID 'AKIAIOSFODNN7EXAMPLE',
SECRET 'wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY',
REGION 'eu-west-1'
)
SELECT * FROM delta_scan('s3://some-bucket/path/to/a/delta/table');
Do you have multiple Delta tables, with different credentials? No problem, you can use scoped secrets:
CREATE SECRET delta_s3 (
TYPE s3,
KEY_ID 'AKIAIOSFODNN7EXAMPLE1',
SECRET 'wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY1',
REGION 'eu-west-1',
SCOPE 's3://some-bucket-1'
)
CREATE SECRET delta_s4 (
TYPE s3,
KEY_ID 'AKIAIOSFODNN7EXAMPLE2',
SECRET 'wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY2',
REGION 'us-west-1',
SCOPE 's3://some-bucket-2'
)
SELECT * FROM delta_scan('s3://some-bucket-1/table1');
SELECT * FROM delta_scan('s3://some-bucket-2/table2');
Finally, is your table public, but outside the default AWS region? Make sure you set the region using an empty S3 Secret:
CREATE SECRET delta_s5 (
TYPE s3,
REGION 'eu-west-2'
)
SELECT * FROM delta_scan('s3://some-public-bucket/table1');
Current State of the Delta Extension
Currently, the Delta Extension is still considered experimental. This is partly because the Delta extension itself is still very new,
but also because the delta-kernel-rs project it relies on is still experimental. Nevertheless, core Delta scanning features are
already supported by the current version of the Delta extension, such as:
- All data types
- Filter and projection pushdown
- File skipping based on filter pushdown
- Deletion vectors
- Partitioned tables
- Fully parallel scanning
The Delta extension is available on the platforms linux_amd64, linux_arm64, osx_amd64 and osx_arm64. Support for the remaining platforms is coming soon. Additionally, we will continue to work together with Databricks on further improving the Delta Extension to add more features such as:
- Write support
- Column mapping
- Time travel
- Variant, RowIds
- Wasm support
For details and info on newly added features, keep an eye on the Delta extension docs and repository.
Conclusion
In this blog post, we presented DuckDB's new Delta extension, enabling easy interaction with Delta Lake directly from the comfort of your own DuckDB environment. To do so, we demonstrated what the Delta Lake format looks like by creating a Delta table and analyzing it using DuckDB.
We want to emphasize the fact that by implementing the Delta extension with the delta-kernel-rs library, both DuckDB and
the Delta extension have been kept relatively simple and largely agnostic to the internals of the Delta protocol.
We hope you give the Delta extension a try and look forward to any feedback from the community! Also, if you're attending the 2024 Databricks Data + AI Summit be sure to check out DuckDB co-founder Hannes Mühleisen's talk on Thursday during the keynote and the in-depth breakout session, also on Thursday, for more details on the DuckDB–Delta integration.

