Access 150k+ Datasets from Hugging Face with DuckDB
TL;DR: DuckDB can now read data from Hugging Face via the hf:// prefix.
We are excited to announce that we added support for hf:// paths in DuckDB, providing access to more than 150,000 datasets for artificial intelligence. We worked with Hugging Face to democratize the access, manipulation, and exploration of datasets used to train and evaluate AI models.
Dataset Repositories
Hugging Face is a popular central platform where users can store, share, and collaborate on machine learning models, datasets, and other resources.
A dataset typically includes the following content:
- A
READMEfile: This plain text file provides an overview of the repository and its contents. It often describes the purpose, usage, and specific requirements or dependencies. - Data files: Depending on the type of repository, it can include data files like CSV, Parquet, JSONL, etc. These are the core components of the repository.
A typical repository looks like this:
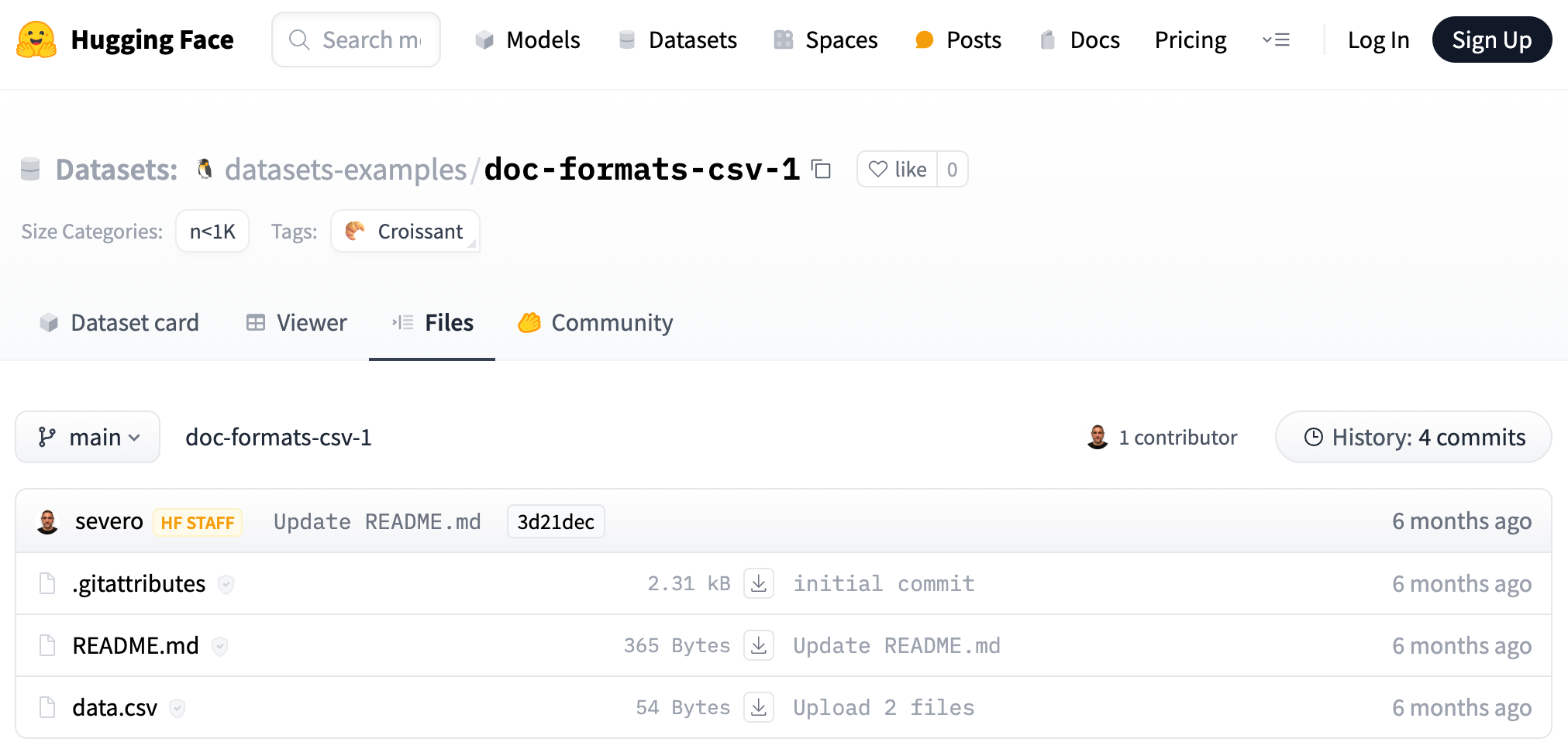
Read Using hf:// Paths
You often need to read files in various formats (such as CSV, JSONL, and Parquet) when working with data. As of version v0.10.3, DuckDB has native support for hf:// paths as part of the httpfs extension, allowing easy access to all these formats.
Now, it is possible to query them using the URL pattern below:
hf://datasets/⟨my_username⟩/⟨my_dataset⟩/⟨path_to_file⟩
For example, to read a CSV file, you can use the following query:
SELECT *
FROM 'hf://datasets/datasets-examples/doc-formats-csv-1/data.csv';
Where:
datasets-examplesis the name of the user/organizationdoc-formats-csv-1is the name of the dataset repositorydata.csvis the file path in the repository
The result of the query is:
| kind | sound |
|---|---|
| dog | woof |
| cat | meow |
| pokemon | pika |
| human | hello |
To read a JSONL file, you can run:
SELECT *
FROM 'hf://datasets/datasets-examples/doc-formats-jsonl-1/data.jsonl';
Finally, for reading a Parquet file, use the following query:
SELECT *
FROM 'hf://datasets/datasets-examples/doc-formats-parquet-1/data/train-00000-of-00001.parquet';
Each of these commands reads the data from the specified file format and displays it in a structured tabular format. Choose the appropriate command based on the file format you are working with.
Creating a Local Table
To avoid accessing the remote endpoint for every query, you can save the data in a DuckDB table by running a CREATE TABLE ... AS command. For example:
CREATE TABLE data AS
SELECT *
FROM 'hf://datasets/datasets-examples/doc-formats-csv-1/data.csv';
Then, simply query the data table as follows:
SELECT *
FROM data;
Multiple Files
You might need to query multiple files simultaneously when working with large datasets. Let's see a quick sample using the cais/mmlu (Measuring Massive Multitask Language Understanding) dataset. This dataset captures a test consisting of multiple-choice questions from various branches of knowledge. It covers 57 tasks, including elementary mathematics, US history, computer science, law, and more. To attain high accuracy on this test, AI models must possess extensive world knowledge and problem-solving ability.
First, let's count the number of rows in individual files. To get the row count from a single file in the cais/mmlu dataset, use the following query:
SELECT count(*) AS count
FROM 'hf://datasets/cais/mmlu/astronomy/dev-00000-of-00001.parquet';
| count |
|---|
| 5 |
Similarly, for another file (test-00000-of-00001.parquet) in the same dataset, we can run:
SELECT count(*) AS count
FROM 'hf://datasets/cais/mmlu/astronomy/test-00000-of-00001.parquet';
| count |
|---|
| 152 |
To query all files under a specific format, you can use a glob pattern. Here’s how you can count the rows in all files that match the pattern *.parquet:
SELECT count(*) AS count
FROM 'hf://datasets/cais/mmlu/astronomy/*.parquet';
| count |
|---|
| 173 |
By using glob patterns, you can efficiently handle large datasets and perform comprehensive queries across multiple files, simplifying your data inspections and processing tasks. Here, you can see how you can look for questions that contain the word “planet” in astronomy:
SELECT count(*) AS count
FROM 'hf://datasets/cais/mmlu/astronomy/*.parquet'
WHERE question LIKE '%planet%';
| count |
|---|
| 21 |
And see some examples:
SELECT question
FROM 'hf://datasets/cais/mmlu/astronomy/*.parquet'
WHERE question LIKE '%planet%'
LIMIT 3;
| question |
|---|
| Why isn't there a planet where the asteroid belt is located? |
| On which planet in our solar system can you find the Great Red Spot? |
| The lithosphere of a planet is the layer that consists of |
Versioning and Revisions
In Hugging Face repositories, dataset versions or revisions are different dataset updates. Each version is a snapshot at a specific time, allowing you to track changes and improvements. In git terms, it can be understood as a branch or specific commit.
You can query different dataset versions/revisions by using the following URL:
hf://datasets/my_username/my_dataset@my_branch/path_to_file
For example:
SELECT *
FROM 'hf://datasets/datasets-examples/doc-formats-csv-1@~parquet/**/*.parquet';
| kind | sound |
|---|---|
| dog | woof |
| cat | meow |
| pokemon | pika |
| human | hello |
The previous query will read all Parquet files under the ~parquet revision. This is a special branch where Hugging Face automatically generates the Parquet files of every dataset to enable efficient scanning.
Authentication
Configure your Hugging Face Token in the DuckDB Secrets Manager to access private or gated datasets. First, visit Hugging Face Settings – Tokens to obtain your access token. Second, set it in your DuckDB session using DuckDB’s Secrets Manager. DuckDB supports two providers for managing secrets:
-
CONFIG: The user must pass all configuration information into theCREATE SECRETstatement. To create a secret using theCONFIGprovider, use the following command:CREATE SECRET hf_token ( TYPE huggingface, TOKEN 'your_hf_token' ); -
credential_chain: Automatically tries to fetch credentials. For the Hugging Face token, it will try to get it from~/.cache/huggingface/token. To create a secret using thecredential_chainprovider, use the following command:CREATE SECRET hf_token ( TYPE huggingface, PROVIDER credential_chain );
Conclusion
The integration of hf:// paths in DuckDB significantly streamlines accessing and querying over 150,000 datasets available on Hugging Face. This feature democratizes data manipulation and exploration, making it easier for users to interact with various file formats such as CSV, JSON, JSONL, and Parquet. By utilizing hf:// paths, users can execute complex queries, efficiently handle large datasets, and harness the extensive resources of Hugging Face repositories.
The integration supports seamless access to individual files, multiple files using glob patterns, and different dataset versions. DuckDB's robust capabilities ensure a flexible and streamlined data processing experience. This integration is a significant leap forward in making AI dataset access more accessible and efficient for researchers and developers, fostering innovation and accelerating progress in machine learning.
Want to learn more about leveraging DuckDB with Hugging Face datasets? Explore the detailed guide.

