
DuckDB's CSV Sniffer: Automatic Detection of Types and Dialects

TL;DR: DuckDB is primarily focused on performance, leveraging the capabilities of modern file formats. At the same time, we also pay attention to flexible, non-performance-driven formats like CSV files. To create a nice and pleasant experience when reading from CSV files, DuckDB implements a CSV sniffer that automatically detects CSV dialect options, column types, and even skips dirty data. The sniffing process allows users to efficiently explore CSV files without needing to provide any input about the file format.

There are many different file formats that users can choose from when storing their data. For example, there are performance-oriented binary formats like Parquet, where data is stored in a columnar format, partitioned into row groups, and heavily compressed. However, Parquet is known for its rigidity, requiring specialized systems to read and write these files.
On the other side of the spectrum, there are files with the CSV (comma-separated values) format, which I like to refer to as the 'Woodstock of data'. CSV files offer the advantage of flexibility; they are structured as text files, allowing users to manipulate them with any text editor, and nearly any data system can read and execute queries on them.
However, this flexibility comes at a cost. Reading a CSV file is not a trivial task, as users need a significant amount of prior knowledge about the file. For instance, DuckDB's CSV reader offers more than 25 configuration options. I've found that people tend to think I'm not working hard enough if I don't introduce at least three new options with each release. Just kidding. These options include specifying the delimiter, quote and escape characters, determining the number of columns in the CSV file, and identifying whether a header is present while also defining column types. This can slow down an interactive data exploration process, and make analyzing new datasets a cumbersome and less enjoyable task.
One of the raison d'être of DuckDB is to be pleasant and easy to use, so we don't want our users to have to fiddle with CSV files and input options manually. Manual input should be reserved only for files with rather unusual choices for their CSV dialect (where a dialect comprises the combination of the delimiter, quote, escape, and newline values used to create that file) or for specifying column types.
Automatically detecting CSV options can be a daunting process. Not only are there many options to investigate, but their combinations can easily lead to a search space explosion. This is especially the case for CSV files that are not well-structured. Some might argue that CSV files have a specification, but the truth of the matter is that the "specification" changes as soon as a single system is capable of reading a flawed file. And, oh boy, I've encountered my fair share of semi-broken CSV files that people wanted DuckDB to read in the past few months.
DuckDB implements a multi-hypothesis CSV sniffer that automatically detects dialects, headers, date/time formats, column types, and identifies dirty rows to be skipped. Our ultimate goal is to automatically read anything resembling a CSV file, to never give up and never let you down! All of this is achieved without incurring a substantial initial cost when reading CSV files. In the bleeding edge version, the sniffer runs when reading a CSV file by default. Note that the sniffer will always prioritize any options set by the user (e.g., if the user sets , as the delimiter, the sniffer won't try any other options and will assume that the user input is correct).
In this blog post, I will explain how the current implementation works, discuss its performance, and provide insights into what comes next!
DuckDB's Automatic Detection
The process of parsing CSV files is depicted in the figure below. It currently consists of five different phases, which will be detailed in the next sections.
The CSV file used in the overview example is as follows:
Name, Height, Vegetarian, Birthday
"Pedro", 1.73, False, 30-07-92
... imagine 2048 consistent rows ...
"Mark", 1.72, N/A, 20-09-92
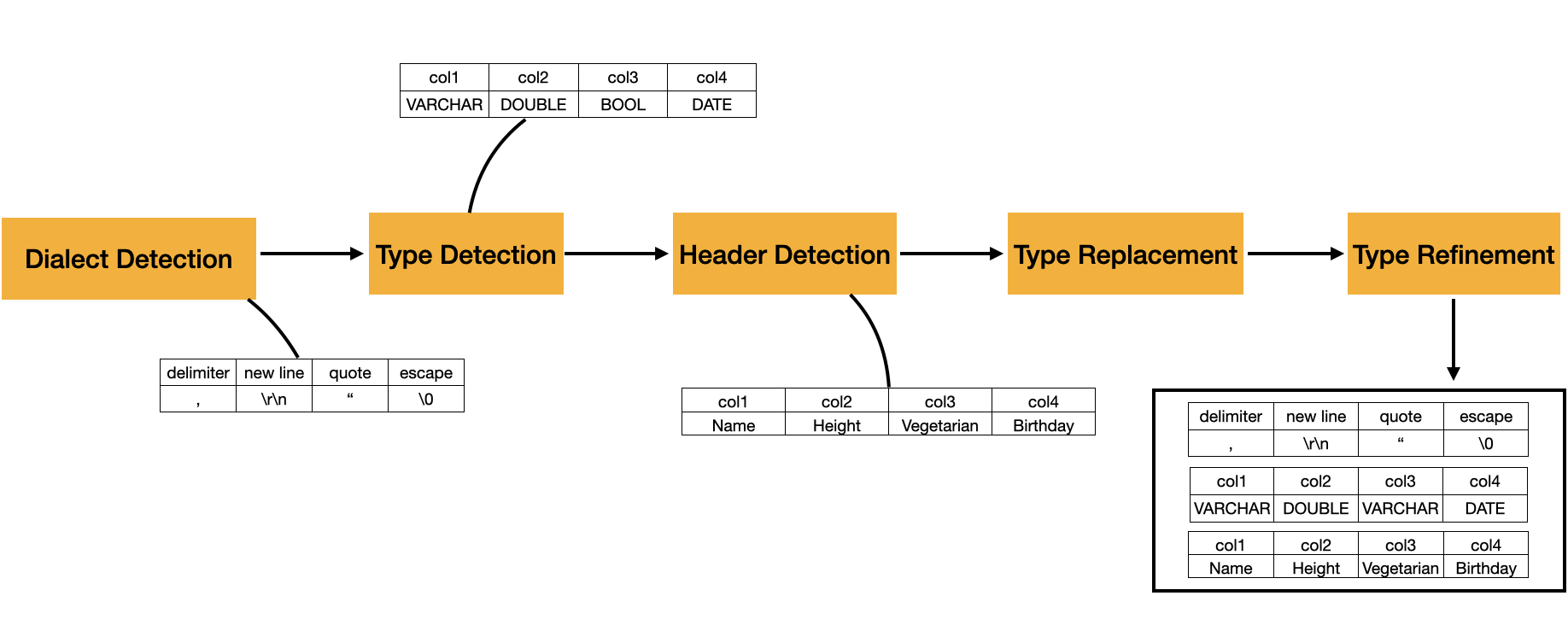
In the first phase, we perform Dialect Detection, where we select the dialect candidates that generate the most per-row columns in the CSV file while maintaining consistency (i.e., not exhibiting significant variations in the number of columns throughout the file). In our example, we can observe that, after this phase, the sniffer successfully detects the necessary options for the delimiter, quotes, escapes, and new line delimiters.
The second phase, referred to as Type Detection, involves identifying the data types for each column in our CSV file. In our example, our sniffer recognizes four column types: VARCHAR, DOUBLE, BOOL, and DATE.
The third step, known as Header Detection, is employed to ascertain whether our file includes a header. If a header is present, we use it to set the column names; otherwise, we generate them automatically. In our example, there is a header, and each column gets its name defined in there.
Now that our columns have names, we move on to the fourth, optional phase: Type Replacement. DuckDB's CSV reader provides users with the option to specify column types by name. If these types are specified, we replace the detected types with the user's specifications.
Finally, we progress to our last phase, Type Refinement. In this phase, we analyze additional sections of the file to validate the accuracy of the types determined during the initial type detection phase. If necessary, we refine them. In our example, we can see that the Vegetarian column was initially categorized as BOOL. However, upon further examination, it was found to contain the string N/A, leading to an upgrade of the column type to VARCHAR to accommodate all possible values.
The automatic detection is only executed on a sequential sample of the CSV file. By default, the size of the sample is 20,480 tuples (i.e., 10 DuckDB execution chunks). This can be configured via the sample_size option, and can be set to -1 in case the user wants to sniff the complete file. Since the same data is repeatedly read with various options, and users can scan the entire file, all CSV buffers generated during sniffing are cached and efficiently managed to ensure high performance.
Of course, running the CSV Sniffer on very large files will have a drastic impact on the overall performance (see our benchmark section below). In these cases, the sample size should be kept at a reasonable level.
In the next subsections, I will describe each phase in detail.
Dialect Detection
In the Dialect Detection, we identify the delimiter, quotes, escapes, and new line delimiters of a CSV file.
Our delimiter search space consists of the following delimiters: ,, |, ;, \t. If the file has a delimiter outside the search space, it must be provided by the user (e.g., delim='?'). Our quote search space is ", ' and \0, where \0 is a string terminator indicating no quote is present; again, users can provide custom characters outside the search space (e.g., quote='?'). The search space of escape values depends on the value of the quote option, but in summary, they are the same as quotes with the addition of \, and again, they can also be provided by the user (escape='?'). Finally, the last detected option is the new line delimiters; they can be \r, \n, \r\n, and a mix of everything (trust me, I've seen a real-world CSV file that used a mix).
By default, the dialect detection runs on 24 different combinations of dialect configurations. To determine the most promising configuration, we calculate the number of columns each CSV tuple would produce under each of these configurations. The one that results in the most columns with the most consistent rows will be chosen.
The calculation of consistent rows depends on additional user-defined options. For example, the null_padding option will pad missing columns with NULL values. Therefore, rows with missing columns will have the missing columns padded with NULL.
If null_padding is set to true, CSV files with inconsistent rows will still be considered, but a preference will be given to configurations that minimize the occurrence of padded rows. If null_padding is set to false, the dialect detector will skip inconsistent rows at the beginning of the CSV file. As an example, consider the following CSV file.
I like my csv files to have notes to make dialect detection harder
I also like commas like this one : ,
A,B,C
1,2,3
4,5,6
Here the sniffer would detect that with the delimiter set to , the first row has one column, the second has two, but the remaining rows have 3 columns. Hence, if null_padding is set to false, it would still select , as a delimiter candidate, by assuming the top rows are dirty notes. (Believe me, CSV notes are a thing!). Resulting in the following table:
A,B,C
1, 2, 3
4, 5, 6
If null_padding is set to true, all lines would be accepted, resulting in the following table:
'I like my csv files to have notes to make dialect detection harder', None, None
'I also like commas like this one : ', None, None
'A', 'B', 'C'
'1', '2', '3'
'4', '5', '6'
If the ignore_errors option is set, then the configuration that yields the most columns with the least inconsistent rows will be picked.
Type Detection
After deciding the dialect that will be used, we detect the types of each column. Our Type Detection considers the following types: SQLNULL, BOOLEAN, BIGINT, DOUBLE, TIME, DATE, TIMESTAMP, VARCHAR. These types are ordered in specificity, which means we first check if a column is a SQLNULL; if not, if it's a BOOLEAN, and so on, until it can only be a VARCHAR. DuckDB has more types than the ones used by default. Users can also define which types the sniffer should consider via the auto_type_candidates option.
At this phase, the type detection algorithm goes over the first chunk of data (i.e., 2048 tuples). This process starts on the second valid row (i.e., not a note) of the file. The first row is stored separately and not used for type detection. It will be later detected if the first row is a header or not. The type detection runs a per-column, per-value casting trial process to determine the column types. It starts off with a unique, per-column array with all types to be checked. It tries to cast the value of the column to that type; if it fails, it removes the type from the array, attempts to cast with the new type, and continues that process until the whole chunk is finished.
At this phase, we also determine the format of DATE and TIMESTAMP columns. The following formats are considered for DATE columns:
%m-%d-%Y%m-%d-%y%d-%m-Y%d-%m-%y%Y-%m-%d%y-%m-%d
The following are considered for TIMESTAMP columns:
%Y-%m-%dT%H:%M:%S.%f%Y-%m-%d %H:%M:%S.%f%m-%d-%Y %I:%M:%S %p%m-%d-%y %I:%M:%S %p%d-%m-%Y %H:%M:%S%d-%m-%y %H:%M:%S%Y-%m-%d %H:%M:%S%y-%m-%d %H:%M:%S
For columns that use formats outside this search space, they must be defined with the dateformat and timestampformat options.
As an example, let's consider the following CSV file.
Name, Age
,
Jack Black, 54
Kyle Gass, 63.2
The first row [Name, Age] will be stored separately for the header detection phase. The second row [NULL, NULL] will allow us to cast the first and second columns to SQLNULL. Therefore, their type candidate arrays will be the same: [SQLNULL, BOOLEAN, BIGINT, DOUBLE, TIME, DATE, TIMESTAMP, VARCHAR].
In the third row [Jack Black, 54], things become more interesting. With 'Jack Black,' the type candidate array for column 0 will exclude all values with higher specificity, as 'Jack Black' can only be converted to a VARCHAR. The second column cannot be converted to either SQLNULL or BOOLEAN, but it will succeed as a BIGINT. Hence, the type candidate for the second column will be [BIGINT, DOUBLE, TIME, DATE, TIMESTAMP, VARCHAR].
In the fourth row, we have [Kyle Gass, 63.2]. For the first column, there's no problem since it's also a valid VARCHAR. However, for the second column, a cast to BIGINT will fail, but a cast to DOUBLE will succeed. Hence, the new array of candidate types for the second column will be [DOUBLE, TIME, DATE, TIMESTAMP, VARCHAR].
Header Detection
The Header Detection phase simply obtains the first valid line of the CSV file and attempts to cast it to the candidate types in our columns. If there is a cast mismatch, we consider that row as the header; if not, we treat the first row as actual data and automatically generate a header.
In our previous example, the first row was [Name, Age], and the column candidate type arrays were [VARCHAR] and [DOUBLE, TIME, DATE, TIMESTAMP, VARCHAR]. Name is a string and can be converted to VARCHAR. Age is also a string, and attempting to cast it to DOUBLE will fail. Since the casting fails, the auto-detection algorithm considers the first row as a header, resulting in the first column being named Name and the second as Age.
If a header is not detected, column names will be automatically generated with the pattern column${x}, where x represents the column's position (0-based index) in the CSV file.
Type Replacement
Now that the auto-detection algorithm has discovered the header names, if the user specifies column types, the types detected by the sniffer will be replaced with them in the Type Replacement phase. For example, we can replace the Age type with FLOAT by using:
SELECT *
FROM read_csv('greatest_band_in_the_world.csv', types = {'Age': 'FLOAT'});
This phase is optional and will only be triggered if there are manually defined types.
Type Refinement
The Type Refinement phase performs the same tasks as type detection; the only difference is the granularity of the data on which the casting operator works, which is adjusted for performance reasons. During type detection, we conduct cast checks on a per-column, per-value basis.
In this phase, we transition to a more efficient vectorized casting algorithm. The validation process remains the same as in type detection, with types from type candidate arrays being eliminated if a cast fails.
How Fast Is the Sniffing?
To analyze the impact of running DuckDB's automatic detection, we execute the sniffer on the NYC taxi dataset. The file consists of 19 columns, 10,906,858 tuples and is 1.72 GB in size.
The cost of sniffing the dialect column names and types is approximately 4% of the total cost of loading the data.
| Name | Time (s) |
|---|---|
| Sniffing | 0.11 |
| Loading | 2.43 |
Varying Sampling Size
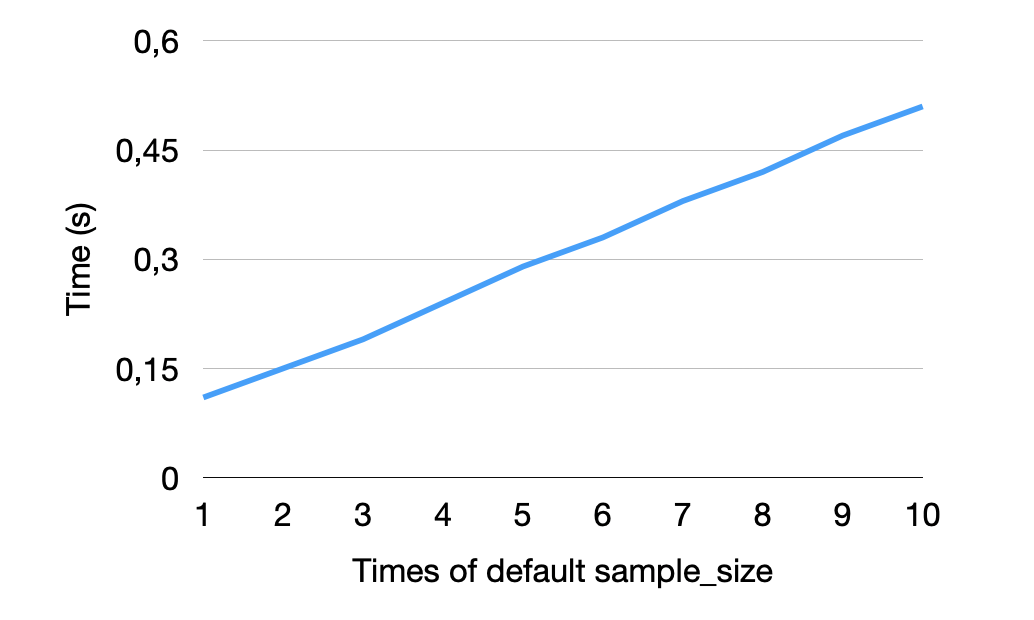
Sometimes, CSV files can have dialect options or more refined types that appear only later in the CSV file. In those cases, the sample_size option becomes an important tool for users to ensure that the sniffer examines enough data to make the correct decision. However, increasing the sample_size also leads to an increase in the total runtime of the sniffer because it uses more data to detect all possible dialects and types.
Below, you can see how increasing the default sample size by multiplier (see X axis) affects the sniffer's runtime on the NYC dataset. As expected, the total time spent on sniffing increases linearly with the total sample size.
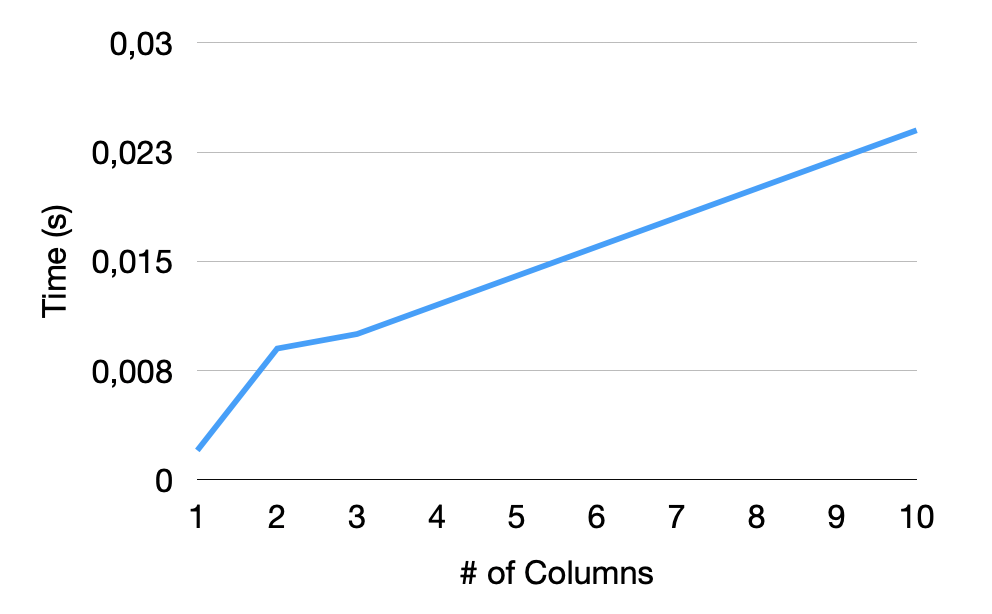
Varying Number of Columns
The other main characteristic of a CSV file that will affect the auto-detection is the number of columns the file has. Here, we test the sniffer against a varying number of INTEGER type columns in files with 10,906,858 tuples. The results are depicted in the figure below. We can see that from one column to two, we have a steeper increase in runtime. That's because, for single columns, we have a simplified dialect detection due to the lack of delimiters. For the other columns, as expected, we have a more linear increase in runtime, depending on the number of columns.
Conclusion & Future Work
If you have unusual CSV files and want to query, clean up, or normalize them, DuckDB is already one of the top solutions available. It is very easy to get started. To read a CSV file with the sniffer, you can simply:
SELECT *
FROM 'path/to/csv_file.csv';
DuckDB's CSV auto-detection algorithm is an important tool to facilitate the exploration of CSV files. With its default options, it has a low impact on the total cost of loading and reading CSV files. Its main goal is to always be capable of reading files, doing a best-effort job even on files that are ill-defined.
We have a list of points related to the sniffer that we would like to improve in the future.
- Advanced Header Detection. We currently determine if a CSV has a header by identifying a type mismatch between the first valid row and the remainder of the CSV file. However, this can generate false negatives if, for example, all the columns of a CSV are of a type
VARCHAR. We plan on enhancing our Header Detection to perform matches with commonly used names for headers. - Adding Accuracy and Speed Benchmarks. We currently implement many accuracy and regression tests; however, due to the CSV's inherent flexibility, manually creating test cases is quite daunting. The plan moving forward is to implement a whole accuracy and regression test suite using the Pollock Benchmark
- Improved Sampling. We currently execute the auto-detection algorithm on a sequential sample of data. However, it's very common that new settings are only introduced later in the file (e.g., quotes might be used only in the last 10% of the file). Hence, being able to execute the sniffer in distinct parts of the file can improve accuracy.
- Multi-Table CSV File. Multiple tables can be present in the same CSV file, which is a common scenario when exporting spreadsheets to CSVs. Therefore, we would like to be able to identify and support these.
- Null-String Detection. We currently do not have an algorithm in place to identify the representation of null strings.
- Decimal Precision Detection. We also don't automatically detect decimal precision yet. This is something that we aim to tackle in the future.
- Parallelization. Despite DuckDB's CSV Reader being fully parallelized, the sniffer is still limited to a single thread. Parallelizing it in a similar fashion to what is done with the CSV Reader (description coming in a future blog post) would significantly enhance sniffing performance and enable full-file sniffing.
- Sniffer as a stand-alone function. Currently, users can utilize the
DESCRIBEquery to acquire information from the sniffer, but it only returns column names and types. We aim to expose the sniffing algorithm as a stand-alone function that provides the complete results from the sniffer. This will allow users to easily configure files using the exact same options without the need to rerun the sniffer.

