
DuckDB ADBC – Zero-Copy Data Transfer via Arrow Database Connectivity

TL;DR: DuckDB has added support for Arrow Database Connectivity (ADBC), an API standard that enables efficient data ingestion and retrieval from database systems, similar to Open Database Connectivity (ODBC) interface. However, unlike ODBC, ADBC specifically caters to the columnar storage model, facilitating fast data transfers between a columnar database and an external application.
![]()
Database interface standards allow developers to write application code that is independent of the underlying database management system (DBMS) being used. DuckDB has supported two standards that have gained popularity in the past few decades: the core interface of ODBC and Java Database Connectivity (JDBC). Both interfaces are designed to fully support database connectivity and management, with JDBC being catered for the Java environment. With these APIs, developers can query DBMS agnostically, retrieve query results, run prepared statements, and manage connections.
These interfaces were designed in the early 90s when row-wise database systems reigned supreme. As a result, they were primarily intended for transferring data in a row-wise format. However, in the mid-2000s, columnar-wise database systems started gaining a lot of traction due to their drastic performance advantages for data analysis (you can find myself giving a brief exemplification of this difference at EuroPython). This means that these APIs offer no support for transferring data in a columnar-wise format (or, in the case of ODBC, some support with a lot of added complexity). In practice, when analytical, column-wise systems like DuckDB make use of these APIs, converting the data between these representation formats becomes a major bottleneck.
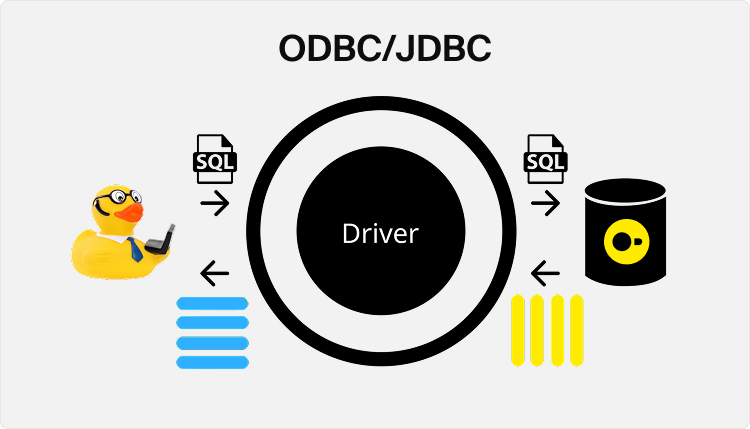
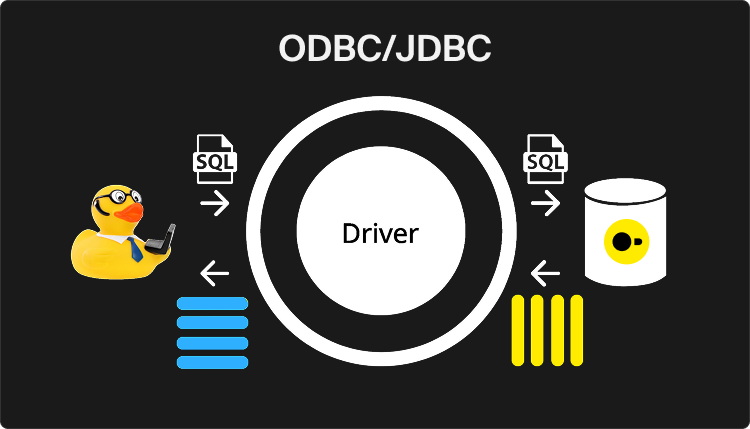
The figure below depicts how a developer can use these APIs to query a DuckDB database. For example, developers can submit SQL queries via the API, which then uses a DuckDB driver to internally call the proper functions. A query result is then produced in DuckDB's internal columnar representation, and the driver takes care of transforming it to the JDBC or ODBC row-wise result format. This transformation has significant costs for rearranging and copying the data, quickly becoming a major bottleneck.
To overcome this transformation cost, ADBC has been proposed, with a generic API to support database operations while using the Apache Arrow memory format to send data in and out of the DBMS. DuckDB now supports the ADBC specification. Due to DuckDB's zero-copy integration with the Arrow format, using ADBC as an interface is rather efficient, since there is only a small constant cost to transform DuckDB query results to the Arrow format.
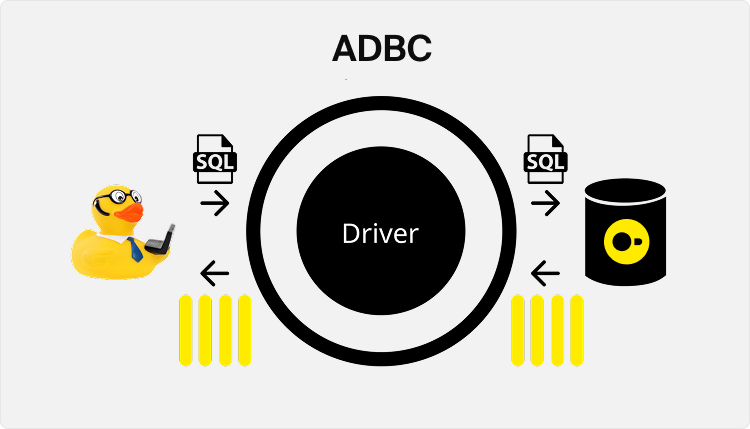
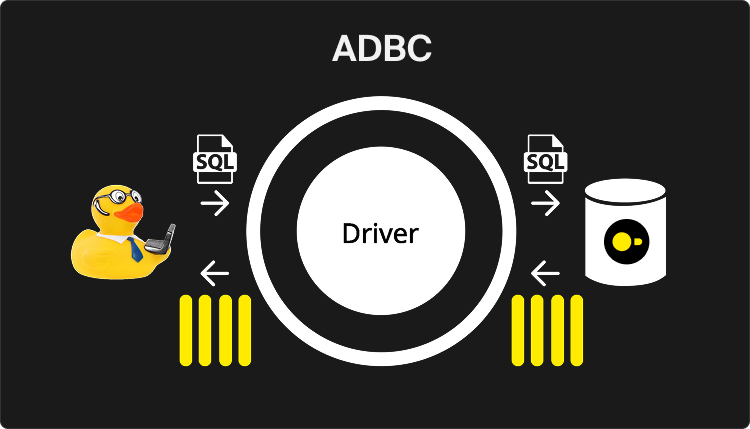
The figure below depicts the query execution flow when using ADBC. Note that the main difference between ODBC/JDBC is that the result does not need to be transformed to a row-wise format.
Quick Tour
For our quick tour, we will illustrate an example of round-tripping data using DuckDB-ADBC via Python. Please note that DuckDB-ADBC can also be utilized with other programming languages. Specifically, you can find C++ DuckDB-ADBC examples and tests in the DuckDB GitHub repository along with usage examples available in C++. For convenience, you can also find a ready-to-run version of this tour in a Colab notebook. If you would like to see a more detailed explanation of the DuckDB-ADBC API or view a C++ example, please refer to our documentation page.
Setup
For this example, you must have a dynamic library from the latest bleeding-edge version of DuckDB, pyarrow, and the adbc-driver-manager. The ADBC driver manager is a Python package developed by Voltron Data. The driver manager is compliant with DB-API 2.0. It wraps ADBC, making its usage more straightforward. For details on ADBC drivers, see the find the documentation of the ADBC Driver Manager.
While DuckDB is already DB-API compliant in Python, what sets ADBC apart is that you do not need a DuckDB module installed and loaded. Additionally, unlike the DB-API, it does not utilize row-wise as its data transfer format of choice.
pip install pyarrow
pip install adbc-driver-manager
Insert Data
First, we need to include the necessary libraries that will be used in this tour. Mainly, PyArrow and the DBAPI from the ADBC Driver Manager.
import pyarrow
from adbc_driver_manager import dbapi
Next, we can create a connection via ADBC with DuckDB. This connection simply requires the path to DuckDB's driver and the entrypoint function name. DuckDB's entrypoint is duckdb_adbc_init.
By default, connections are established with an in-memory database. However, if desired, you have the option to specify the path variable and connect to a local DuckDB instance, allowing you to store the data on disk.
Note that these are the only variables in ADBC that are not DBMS agnostic; instead, they are set by the user, often through a configuration file.
con = dbapi.connect(driver="path/to/duckdb.lib", entrypoint="duckdb_adbc_init", db_kwargs={"path": "test.db"})
To insert the data, we can simply call the adbc_ingest function with a cursor from our connection. It requires the name of the table we want to perform the ingestion to and the Arrow Python object we want to ingest. This function also has two modes: append, where data is appended to an existing table, and create, where the table does not exist yet and will be created with the input data. By default, it's set to create, so we don't need to define it here.
table = pyarrow.table(
[
["Tenacious D", "Backstreet Boys", "Wu Tang Clan"],
[4, 10, 7]
],
names=["Name", "Albums"],
)
with con.cursor() as cursor:
cursor.adbc_ingest("Bands", table)
After calling adbc_ingest, the table is created in the DuckDB connection and the data is fully inserted.
Read Data
To read data from DuckDB, one simply needs to use the execute function with a SQL query and then return the cursor's result to the desired Arrow format, such as a PyArrow Table in this example.
with con.cursor() as cursor:
cursor.execute("SELECT * FROM Bands")
cursor.fetch_arrow_table()
Benchmark ADBC vs ODBC
In our benchmark section, we aim to evaluate the differences in data reading from DuckDB via ADBC and ODBC. This benchmark was executed on an Apple M1 Max with 32 GB of RAM and involves outputting and inserting the lineitem table of TPC-H SF1. You can find the repository with the code used to run this benchmark on GitHub.
| Name | Time (s) |
|---|---|
| ODBC | 28.149 |
| ADBC | 0.724 |
The time difference between ODBC and ADBC is 38×. This significant contrast results from the extra allocations and copies that exist in ODBC.
Conclusions
DuckDB now supports the ADBC standard for database connection. ADBC is particularly efficient when combined with DuckDB, thanks to its use of the Arrow zero-copy integration.
ADBC is particularly interesting because it can drastically decrease interactions between analytic systems compared to ODBC. For example, if software that already support ODBC, e.g., if MS-Excel was to implement ADBC, integrations with columnar systems like DuckDB could benefit from this significant difference in performance.
DuckDB-ADBC is currently supported via the C Interface and through the Python ADBC Driver Manager. We will add more extensive tutorials for other languages to our documentation webpage. Please feel free to let us know your preferred language for interacting with DuckDB via ADBC!
If you encounter any problems using ADBC, please open an issue in DuckDB's issue tracker.

