
DuckDB – Lord of the Enums: The Fellowship of the Categorical and Factors


String types are one of the most commonly used types. However, often string columns have a limited number of distinct values. For example, a country column will never have more than a few hundred unique entries. Storing a data type as a plain string causes a waste of storage and compromises query performance. A better solution is to dictionary encode these columns. In dictionary encoding, the data is split into two parts: the category and the values. The category stores the actual strings, and the values stores a reference to the strings. This encoding is depicted below.
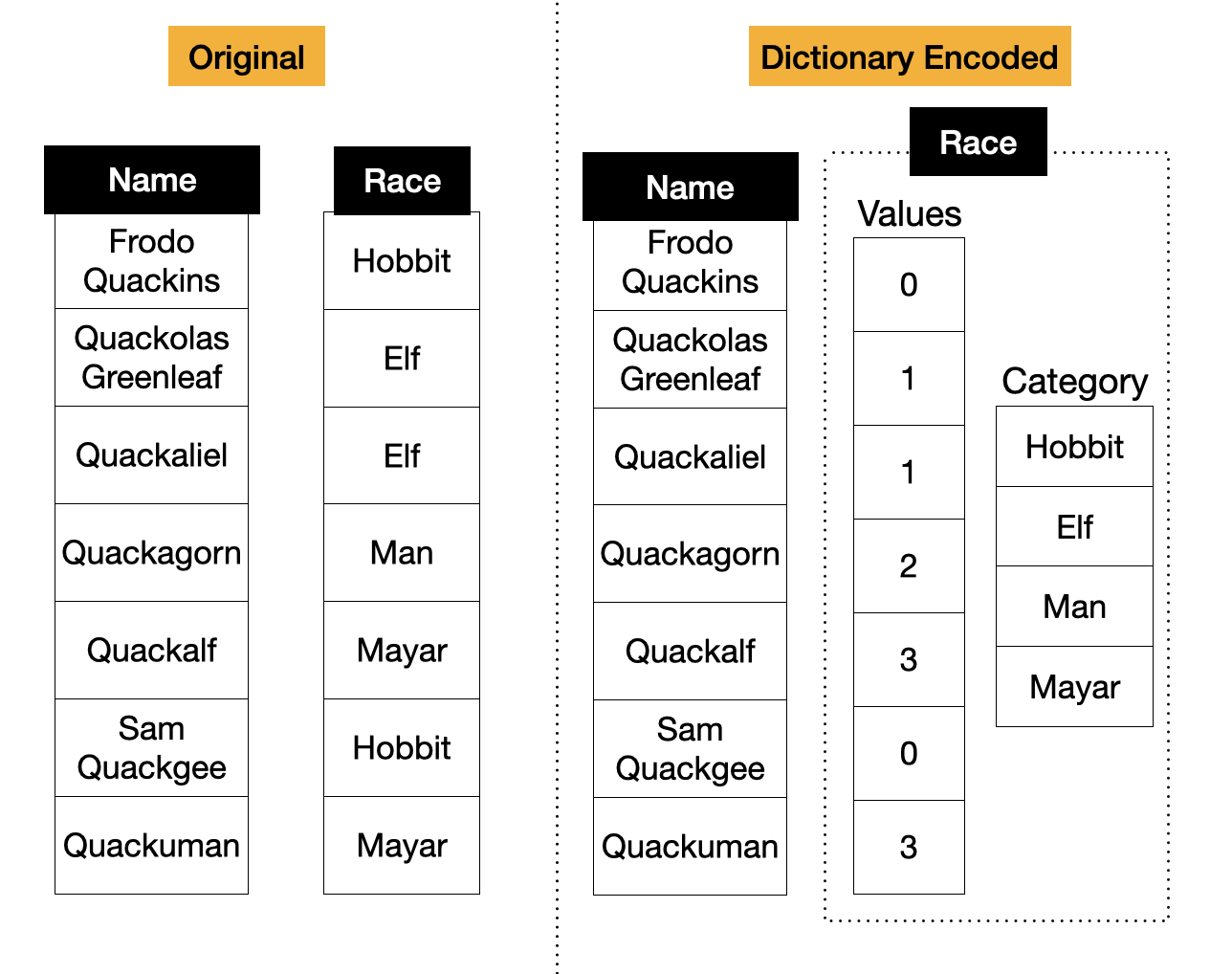
In the old times, users would manually perform dictionary encoding by creating lookup tables and translating their ids back with join operations. Environments like Pandas and R support these types more elegantly. Pandas Categorical and R Factors are types that allow for columns of strings with many duplicate entries to be efficiently stored through dictionary encoding.
Dictionary encoding not only allows immense storage savings but also allows systems to operate on numbers instead of on strings, drastically boosting query performance. By lowering RAM usage, ENUMs also allow DuckDB to scale to significantly larger datasets.
To allow DuckDB to fully integrate with these encoded structures, we implemented Enum Types. This blog post will show code snippets of how to use ENUM types from both SQL API and Python/R clients, and will demonstrate the performance benefits of the enum types over using regular strings. To the best of our knowledge, DuckDB is the first RDBMS that natively integrates with Pandas categorical columns and R factors.
SQL
Our Enum SQL syntax is heavily inspired by Postgres. Below, we depict how to create and use the ENUM type.
CREATE TYPE lotr_race AS ENUM ('Mayar', 'Hobbit', 'Orc');
CREATE TABLE character (
name text,
race lotr_race
);
INSERT INTO character VALUES ('Frodo Quackins','Hobbit'), ('Quackalf ', 'Mayar');
-- We can perform a normal string comparison
-- Note that 'Hobbit' will be cast to a lotr_race
-- hence this comparison is actually a fast integer comparison
SELECT name FROM character WHERE race = 'Hobbit';
----
Frodo Quackins
ENUM columns behave exactly the same as normal VARCHAR columns. They can be used in string functions (such as LIKE or substring), they can be compared, ordered, etc. The only exception is that ENUM columns can only hold the values that are specified in the enum definition. Inserting a value that is not part of the enum definition will result in an error.
DuckDB ENUMs are currently static (i.e., values can not be added or removed after the ENUM definition). However, ENUM updates are on the roadmap for the next version.
See the documentation for more information.
Python
Setup
First we need to install DuckDB and Pandas. The installation process of both libraries in Python is straightforward:
# Python Install
pip install duckdb
pip install pandas
Usage
Pandas columns from the categorical type are directly converted to DuckDB's ENUM types:
import pandas as pd
import duckdb
# Our unencoded data.
data = ['Hobbit', 'Elf', 'Elf', 'Man', 'Mayar', 'Hobbit', 'Mayar']
# 'pd.Categorical' automatically encodes the data as a categorical column
df_in = pd.DataFrame({'races': pd.Categorical(data),})
# We can query this dataframe as we would any other
# The conversion from categorical columns to enums happens automatically
df_out = duckdb.execute("SELECT * FROM df_in").df()
R
Setup
We only need to install DuckDB in our R client, and we are ready to go.
# R Install
install.packages("duckdb")
Usage
Similar to our previous example with Pandas, R Factor columns are also automatically converted to DuckDB's ENUM types.
library ("duckdb")
con <- dbConnect(duckdb::duckdb())
on.exit(dbDisconnect(con, shutdown = TRUE))
# Our unencoded data.
data <- c('Hobbit', 'Elf', 'Elf', 'Man', 'Mayar', 'Hobbit', 'Mayar')
# Our R dataframe holding an encoded version of our data column
# 'as.factor' automatically encodes it.
df_in <- data.frame(races=as.factor(data))
duckdb::duckdb_register(con, "characters", df_in)
df_out <- dbReadTable(con, "characters")
Benchmark Comparison
To demonstrate the performance of DuckDB when running operations on categorical columns of Pandas DataFrames, we present a number of benchmarks. The source code for the benchmarks is available on GitHub. In our benchmarks we always consume and produce Pandas DataFrames.
Dataset
Our dataset is composed of one dataframe with 4 columns and 10 million rows. The first two columns are named race and subrace representing races. They are both categorical, with the same categories but different values. The other two columns race_string and subrace_string are the string representations of race and subrace``.
def generate_df(size):
race_categories = ['Hobbit', 'Elf', 'Man', 'Mayar']
race = np.random.choice(race_categories, size)
subrace = np.random.choice(race_categories, size)
return pd.DataFrame({'race': pd.Categorical(race),
'subrace': pd.Categorical(subrace),
'race_string': race,
'subrace_string': subrace,})
size = pow(10,7) #10,000,000 rows
df = generate_df(size)
Grouped Aggregation
In our grouped aggregation benchmark, we do a count of how many characters for each race we have in the race or race_string column of our table.
def duck_categorical(df):
return con.execute("SELECT race, count(*) FROM df GROUP BY race").df()
def duck_string(df):
return con.execute("SELECT race_string, count(*) FROM df GROUP BY race_string").df()
def pandas(df):
return df.groupby(['race']).agg({'race': 'count'})
def pandas_string(df):
return df.groupby(['race_string']).agg({'race_string': 'count'})
The table below depicts the timings of this operation. We can see the benefits of performing grouping on encoded values over strings, with DuckDB being 4× faster when grouping small unsigned values.
| Name | Time (s) |
|---|---|
| DuckDB (Categorical) | 0.01 |
| DuckDB (String) | 0.04 |
| Pandas (Categorical) | 0.06 |
| Pandas (String) | 0.40 |
Filter
In our filter benchmark, we do a count of how many Hobbit characters we have in the race or race_string column of our table.
def duck_categorical(df):
return con.execute("SELECT count(*) FROM df WHERE race = 'Hobbit'").df()
def duck_string(df):
return con.execute("SELECT count(*) FROM df WHERE race_string = 'Hobbit'").df()
def pandas(df):
filtered_df = df[df.race == "Hobbit"]
return filtered_df.agg({'race': 'count'})
def pandas_string(df):
filtered_df = df[df.race_string == "Hobbit"]
return filtered_df.agg({'race_string': 'count'})
For the DuckDB enum type, DuckDB converts the string Hobbit to a value in the ENUM, which returns an unsigned integer. We can then do fast numeric comparisons, instead of expensive string comparisons, which results in greatly improved performance.
| Name | Time (s) |
|---|---|
| DuckDB (Categorical) | 0.003 |
| DuckDB (String) | 0.023 |
| Pandas (Categorical) | 0.158 |
| Pandas (String) | 0.440 |
Enum – Enum Comparison
In this benchmark, we perform an equality comparison of our two breed columns. race and subrace or race_string and subrace_string``
def duck_categorical(df):
return con.execute("SELECT count(*) FROM df WHERE race = subrace").df()
def duck_string(df):
return con.execute("SELECT count(*) FROM df WHERE race_string = subrace_string").df()
def pandas(df):
filtered_df = df[df.race == df.subrace]
return filtered_df.agg({'race': 'count'})
def pandas_string(df):
filtered_df = df[df.race_string == df.subrace_string]
return filtered_df.agg({'race_string': 'count'})
DuckDB ENUMs can be compared directly on their encoded values. This results in a time difference similar to the previous case, again because we are able to compare numeric values instead of strings.
| Name | Time (s) |
|---|---|
| DuckDB (Categorical) | 0.005 |
| DuckDB (String) | 0.040 |
| Pandas (Categorical) | 0.130 |
| Pandas (String) | 0.550 |
Storage
In this benchmark, we compare the storage savings of storing ENUM Types vs Strings.
race_categories = ['Hobbit', 'Elf', 'Man','Mayar']
race = np.random.choice(race_categories, size)
categorical_race = pd.DataFrame({'race': pd.Categorical(race),})
string_race = pd.DataFrame({'race': race,})
con = duckdb.connect('duck_cat.db')
con.execute("CREATE TABLE character AS SELECT * FROM categorical_race")
con = duckdb.connect('duck_str.db')
con.execute("CREATE TABLE character AS SELECT * FROM string_race")
The table below depicts the DuckDB file size differences when storing the same column as either an Enum or a plain string. Since the dictionary-encoding does not repeat the string values, we can see a reduction of one order of magnitude in size.
| Name | Size (MB) |
|---|---|
| DuckDB (Categorical) | 11 |
| DuckDB (String) | 102 |
What about the Sequels?
There are three main directions we will pursue in the following versions of DuckDB related to ENUMs.
- Automatic Storage Encoding: As described in the introduction, users frequently define database columns as Strings when in reality they are
ENUMs. Our idea is to automatically detect and dictionary-encode these columns, without any input of the user and in a way that is completely invisible to them. ENUMUpdates: As said in the introduction, ourENUMs are currently static. We will allow the insertion and removal ofENUMcategories.- Integration with other Data Formats: We want to expand our integration with data formats that implement
ENUM-like structures.
Feedback
If you encounter any problems when using our ENUMs, please open an issue in our issue tracker!

