Announcing DuckDB 0.10.0
TL;DR: The DuckDB team is happy to announce the latest DuckDB release (0.10.0). This release is named Fusca after the Velvet scoter native to Europe.

To install the new version, please visit the installation guide. The full release notes can be found on GitHub.
What's New in 0.10.0
There have been too many changes to discuss them each in detail, but we would like to highlight several particularly exciting features!
Below is a summary of those new features with examples, starting with a change in our SQL dialect that is designed to produce more intuitive results by default.
Breaking SQL Changes
Implicit Cast to VARCHAR. Previously, DuckDB would automatically allow any type to be implicitly cast to VARCHAR during function binding. As a result it was possible to e.g., compute the substring of an integer without using an implicit cast. Starting with this release, you will need to use an explicit cast here instead.
SELECT substring(42, 1, 1) AS substr;
No function matches the given name and argument types 'substring(...)'.
You might need to add explicit type casts.
To use an explicit cast, run:
SELECT substring(42::VARCHAR, 1, 1) AS substr;
┌─────────┐
│ substr │
│ varchar │
├─────────┤
│ 4 │
└─────────┘
Alternatively, the old_implicit_casting setting can be used to revert this behavior, e.g.:
SET old_implicit_casting = true;
SELECT substring(42, 1, 1) AS substr;
┌─────────┐
│ substr │
│ varchar │
├─────────┤
│ 4 │
└─────────┘
Literal Typing. Previously, integer and string literals behaved identically to the INTEGER and VARCHAR types. Starting with this release, INTEGER_LITERAL and STRING_LITERAL are separate types that have their own binding rules.
INTEGER_LITERALtypes can be implicitly converted to any integer type in which the value fitsSTRING_LITERALtypes can be implicitly converted to any other type
This aligns DuckDB with Postgres, and makes operations on literals more intuitive. For example, we can compare string literals with dates – but we cannot compare VARCHAR values with dates.
SELECT d > '1992-01-01' AS result
FROM (VALUES (DATE '1992-01-01')) t(d);
┌─────────┐
│ result │
│ boolean │
├─────────┤
│ false │
└─────────┘
SELECT d > '1992-01-01'::VARCHAR AS result
FROM (VALUES (DATE '1992-01-01')) t(d);
Binder Error:
Cannot compare values of type DATE and type VARCHAR – an explicit cast is required
Backward Compatibility
Backward compatibility refers to the ability of a newer DuckDB version to read storage files created by an older DuckDB version. This release is the first release of DuckDB that supports backward compatibility in the storage format. DuckDB v0.10 can read and operate on files created by the previous DuckDB version – DuckDB v0.9. This is made possible by the implementation of a new serialization framework.
Write with v0.9:
duckdb_092 v092.db
CREATE TABLE lineitem AS
FROM lineitem.parquet;
Read with v0.10:
duckdb_0100 v092.db
SELECT l_orderkey, l_partkey, l_comment
FROM lineitem
LIMIT 1;
┌────────────┬───────────┬─────────────────────────┐
│ l_orderkey │ l_partkey │ l_comment │
│ int32 │ int32 │ varchar │
├────────────┼───────────┼─────────────────────────┤
│ 1 │ 155190 │ to beans x-ray carefull │
└────────────┴───────────┴─────────────────────────┘
For future DuckDB versions, our goal is to ensure that any DuckDB version released after can read files created by previous versions, starting from this release. We want to ensure that the file format is fully backward compatible. This allows you to keep data stored in DuckDB files around and guarantees that you will be able to read the files without having to worry about which version the file was written with or having to convert files between versions.
Forward Compatibility
Forward compatibility refers to the ability of an older DuckDB version to read storage files produced by a newer DuckDB version. DuckDB v0.9 is partially forward compatible with DuckDB v0.10. Certain files created by DuckDB v0.10 can be read by DuckDB v0.9.
Write with v0.10:
duckdb_0100 v010.db
CREATE TABLE lineitem AS
FROM lineitem.parquet;
Read with v0.9:
duckdb_092 v010.db
SELECT l_orderkey, l_partkey, l_comment
FROM lineitem
LIMIT 1;
┌────────────┬───────────┬─────────────────────────┐
│ l_orderkey │ l_partkey │ l_comment │
│ int32 │ int32 │ varchar │
├────────────┼───────────┼─────────────────────────┤
│ 1 │ 155190 │ to beans x-ray carefull │
└────────────┴───────────┴─────────────────────────┘
Forward compatibility is provided on a best effort basis. While stability of the storage format is important – there are still many improvements and innovations that we want to make to the storage format in the future. As such, forward compatibility may be (partially) broken on occasion.
For this release, DuckDB v0.9 is able to read files created by DuckDB v0.10 provided that:
- The database file does not contain views
- The database file does not contain new types (
ARRAY,UHUGEINT) - The database file does not contain indexes (
PRIMARY KEY,FOREIGN KEY,UNIQUE, explicit indexes) - The database file does not contain new compression methods (
ALP). As ALP is automatically used to compressFLOATandDOUBLEcolumns – that means forward compatibility in practice often does not work forFLOATandDOUBLEcolumns unlessALPis explicitly disabled through configuration.
We expect that as the format stabilizes and matures this will happen less frequently – and we hope to offer better guarantees in allowing DuckDB to read files written by future DuckDB versions.
CSV Reader Rework
CSV Reader Rework. The CSV reader has received a major overhaul in this release. The new CSV reader uses efficient state machine transitions to speed through CSV files. This has greatly sped up performance of the CSV reader, particularly in multi-threaded scenarios. In addition, in the case of malformed CSV files, reported error messages should be more clear.
Below is a benchmark comparing the loading time of 11 million rows of the NYC Taxi dataset from a CSV file on an M1 Max with 10 cores:
| Version | Load time |
|---|---|
| v0.9.2 | 2.6 s |
| v0.10.0 | 1.2 s |
Furthermore, many optimizations have been done that make running queries over CSV files directly significantly faster as well. Below is a benchmark comparing the execution time of a SELECT count(*) query directly over the NYC Taxi CSV file.
| Version | Query time |
|---|---|
| v0.9.2 | 1.8 s |
| v0.10.0 | 0.3 s |
Fixed-Length Arrays
Fixed-Length Arrays. This release introduces the fixed-length array type. Fixed-length arrays are similar to lists, however, every value must have the same fixed number of elements in them.
CREATE TABLE vectors (v DOUBLE[3]);
INSERT INTO vectors VALUES ([1, 2, 3]);
Fixed-length arrays can be operated on faster than variable-length lists as the size of each list element is known ahead of time. This release also introduces specialized functions that operate over these arrays, such as array_cross_product, array_cosine_similarity, and array_inner_product.
SELECT array_cross_product(v, [1, 1, 1]) AS result
FROM vectors;
┌───────────────────┐
│ result │
│ double[3] │
├───────────────────┤
│ [-1.0, 2.0, -1.0] │
└───────────────────┘
See the Array Type page in the documentation for more information.
Multi-Database Support
DuckDB can now attach MySQL, Postgres, and SQLite databases in addition to databases stored in its own format. This allows data to be read into DuckDB and moved between these systems in a convenient manner, as attached databases are fully functional, appear just as regular tables, and can be updated in a safe, transactional manner. More information about multi-database support can be found in our recent blog post.
ATTACH 'sqlite:sakila.db' AS sqlite;
ATTACH 'postgres:dbname=postgresscanner' AS postgres;
ATTACH 'mysql:user=root database=mysqlscanner' AS mysql;
Secret Manager
DuckDB integrates with several cloud storage systems such as S3 that require access credentials to access data. In the current version of DuckDB, authentication information is configured through DuckDB settings, e.g., SET s3_access_key_id = '...';. While this worked, it had several shortcomings. For example, it was not possible to set different credentials for different S3 buckets without modifying the settings between queries. Because settings are not considered secret, it was also possible to query them using duckdb_settings().
With this release, DuckDB adds a new "Secrets Manager" to manage secrets in a better way. We now have a unified user interface for secrets across all backends that use them. Secrets can be scoped, so different storage prefixes can have different secrets, allowing, for example, joining across organizations in a single query. Secrets can also be persisted, so that they do not need to be specified every time DuckDB is launched.
Secrets are typed, their type identifies which service they are for. For example, this release can manage secrets for S3, Google Cloud Storage, Cloudflare R2 and Azure Blob Storage. For each type, there are one or more "secret providers" that specify how the secret is created. Secrets can also have an optional scope, which is a file path prefix that the secret applies to. When fetching a secret for a path, the secret scopes are compared to the path, returning the matching secret for the path. In the case of multiple matching secrets, the longest prefix is chosen.
Finally, secrets can be temporary or persistent. Temporary secrets are used by default – and are stored in-memory for the life span of the DuckDB instance similar to how settings worked previously. Persistent secrets are stored in unencrypted binary format in the ~/.duckdb/stored_secrets directory. On startup of DuckDB, persistent secrets are read from this directory and automatically loaded.
For example, to create a temporary unscoped secret to access S3, we can now use the following syntax:
CREATE SECRET (
TYPE s3,
KEY_ID 'AKIAIOSFODNN7EXAMPLE',
SECRET 'wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY',
REGION 'us-east-1'
);
If two secrets exist for a service type, the scope can be used to decide which one should be used. For example:
CREATE SECRET secret1 (
TYPE s3,
KEY_ID 'my_key1',
SECRET 'my_secret1',
SCOPE 's3://my-bucket'
);
CREATE SECRET secret2 (
TYPE s3,
KEY_ID 'my_key2',
SECRET 'my_secret2',
SCOPE 's3://my-other-bucket'
);
Now, if the user queries something from s3://my-other-bucket/something, secret2 will be chosen automatically for that request.
Secrets can be listed using the built-in table-producing function, e.g., by using FROM duckdb_secrets();. Sensitive information will be redacted.
In order to persist secrets between DuckDB database instances, we can now use the CREATE PERSISTENT SECRET command, e.g.:
CREATE PERSISTENT SECRET my_persistent_secret (
TYPE s3,
KEY_ID 'my_key',
SECRET 'my_secret'
);
As mentioned, this will write the secret (unencrypted, so beware) to the ~/.duckdb/stored_secrets directory.
See the Create Secret page in the documentation for more information.
Temporary Memory Manager
DuckDB has support for larger-than-memory operations, which means that memory-hungry operators such as aggregations and joins can offload part of their intermediate results to temporary files on disk should there not be enough memory available.
Before, those operators started offloading to disk if their memory usage reached around 60% of the available memory (as defined by the memory limit). This works well if there is exactly one of these operations happening at the same time. If multiple memory-intensive operations are happening simultaneously, their combined memory usage may exceed the memory limit, causing DuckDB to throw an error.
This release introduces the so-called "Temporary Memory Manager", which manages the temporary memory of concurrent operations. It works as follows: Memory-intensive operations register themselves with the Temporary Manager. Each registration is guaranteed some minimum amount of memory by the manager depending on the number of threads and the current memory limit. Then, the memory-intensive operations communicate how much memory they would currently like to use. The manager can approve this or respond with a reduced allocation. In a case of a reduced allocation, the operator will need to dynamically reduce its memory requirements, for example by switching algorithms.
For example, a hash join might adapt its operation and perform a partitioned hash join instead of a full in-memory one if not enough memory is available.
Here is an example:
PRAGMA memory_limit = '5GB';
SET temp_directory = '/tmp/duckdb_temporary_memory_manager';
CREATE TABLE tbl AS
SELECT range AS i,
range AS j
FROM range(100_000_000);
SELECT max(i),
max(t1.j),
max(t2.j),
max(t3.j),
FROM tbl AS t1
JOIN tbl AS t2 USING (i)
JOIN tbl AS t3 USING (i);
Note that a temporary directory has to be set here, because the operators actually need to offload data to disk to complete this query given this memory limit.
With the new version 0.10.0, this query completes in ca. 5 s on a MacBook, while it would error out on the previous version with Error: Out of Memory Error: failed to pin block of size ....
Adaptive Lossless Floating-Point Compression (ALP)
Floating point numbers are notoriously difficult to compress efficiently, both in terms of compression ratio as well as speed of compression and decompression. In the past, DuckDB had support for the then state-of-the-art "Chimp" and the "Patas" compression methods. Turns out, those were not the last word in floating point compression. Researchers Azim Afroozeh, Leonard Kuffo and (the one and only) Peter Boncz have recently published a paper titled "ALP: Adaptive Lossless floating-Point Compression" at SIGMOD, a top-tier academic conference for data management research. In an uncommon yet highly commendable move, they have also sent a pull request to DuckDB. The new compression scheme replaces Chimp and Patas. Inside DuckDB, ALP is x2-4 times faster than Patas (at decompression) achieving compression ratios twice as high (sometimes even much more).
| Compression | Load | Query | Size |
|---|---|---|---|
| ALP | 0.434 s | 0.020 s | 184 MB |
| Patas | 0.603 s | 0.080 s | 275 MB |
| Uncompressed | 0.316 s | 0.012 s | 489 MB |
As a user, you don't have to do anything to make use of the new ALP compression method, DuckDB will automatically decide during checkpointing whether using ALP is beneficial for the specific dataset.
CLI Improvements
The command-line client has seen a lot of work this release. In particular, multi-line editing has been made the default mode, and has seen many improvements. The query history is now also multi-line. Syntax highlighting has improved – missing brackets and unclosed quotes are highlighted as errors, and matching brackets are highlighted when the cursor moves over them. Compatibility with read-line has also been greatly extended.
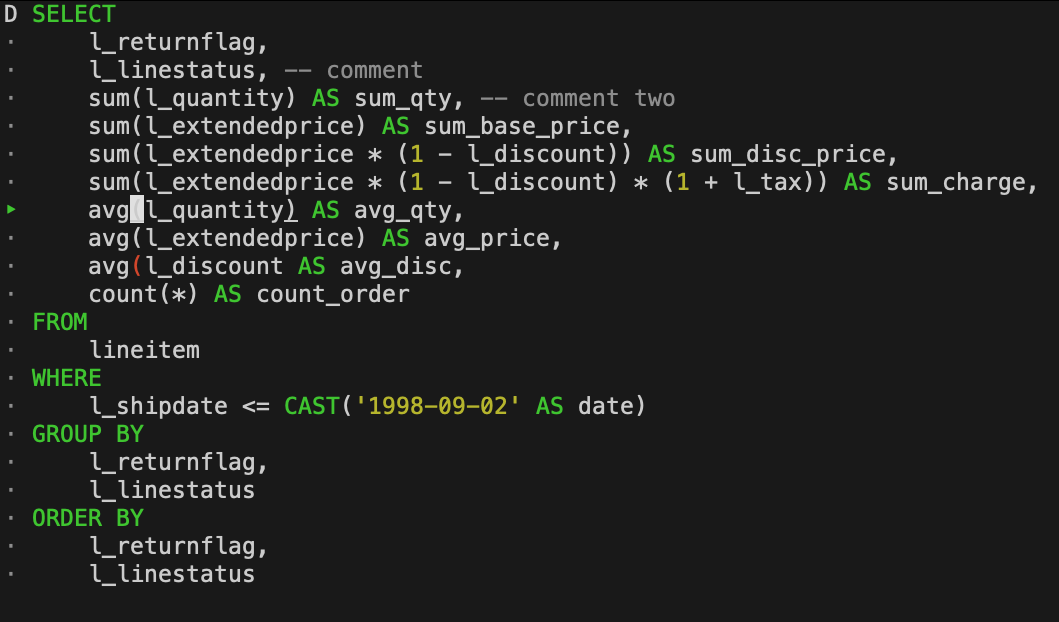
See the extended CLI docs for more information.
Final Thoughts
These were a few highlights – but there are many more features and improvements in this release. Below are a few more highlights. The full release notes can be found on GitHub.
New Features
COMMENT ONCOPY FROM DATABASEUHUGEINTtype- Window
EXCLUDEand WindowDISTINCTsupport - Parquet encryption support
- Indexes for Lambda parameters
EXCEPT ALL/INTERSECT ALLDESCRIBE/SHOW/SUMMARIZEas subquery- Support recursive CTEs in correlated subqueries
New Functions
parquet_kv_metadataandparquet_file_metadatafunctionsread_text/read_blobtable functionslist_reduce,list_where,list_zip,list_select,list_grade_up
Storage Improvements
Optimizations
Acknowledgments
We would like to thank all of the contributors for their hard work on improving DuckDB.