Introducing DuckDB for Swift
TL;DR: DuckDB now has a native Swift API. DuckDB on mobile here we go!
Today we’re excited to announce the DuckDB API for Swift. It enables developers on Swift platforms to harness the full power of DuckDB using a native Swift interface with support for great Swift features such as strong typing and concurrency. The API is available not only on Apple platforms, but on Linux too, opening up new opportunities for the growing Swift on Server ecosystem.
What’s Included
DuckDB is designed to be fast, reliable and easy to use, and it’s this philosophy that also guided the creation of our new Swift API.
This initial release supports many of the great features of DuckDB right out of the box, including:
- Queries via DuckDB’s enhanced SQL dialect: In addition to basic SQL, DuckDB supports arbitrary and nested correlated subqueries, window functions, collations, complex types (Swift arrays and structs), and more.
- Import and export of JSON, CSV, and Parquet files: Beyond its built-in and super-efficient native file format, DuckDB supports reading in, and exporting out to, JSON, CSV, and Parquet files.
- Strongly typed result sets: DuckDB’s strongly typed result sets are a natural fit for Swift. It’s simple to cast DuckDB columns to their native Swift equivalents, ready for presentation using SwiftUI or as part of an existing TabularData workflow.
- Swift concurrency support: by virtue of their
Sendableconformance, many of DuckDB’s core underlying types can be safely passed across concurrency contexts, easing the process of designing parallel processing workflows and ensuring responsive UIs.
Usage
To demonstrate just how well DuckDB works together with Swift, we’ve created an example project that uses raw data from NASA’s Exoplanet Archive loaded directly into DuckDB.
You’ll see how to:
- Instantiate a DuckDB in-memory Database and Connection
- Populate a DuckDB table with the contents of a remote CSV
- Query a DuckDB database and prepare the results for presentation
Finally, we’ll present our analysis with the help of Apple’s TabularData Framework and Swift Charts.
Instantiating DuckDB
DuckDB supports both file-based and in-memory databases. In this example, as we don’t intend to persist the results of our Exoplanet analysis to disk, we’ll opt for an in-memory Database.
let database = try Database(store: .inMemory)
However, we can’t issue queries just yet. Much like other RDMSs, queries must be issued through a database connection. DuckDB supports multiple connections per database. This can be useful to support parallel processing, for example. In our project, we’ll need just the one connection that we’ll eventually access asynchronously.
let connection = try database.connect()
Finally, we’ll create an app-specific type that we’ll use to house our database and connection and through which we’ll eventually define our app-specific queries.
import DuckDB
final class ExoplanetStore {
let database: Database
let connection: Connection
init(database: Database, connection: Connection) {
self.database = database
self.connection = connection
}
}
Populating DuckDB with a Remote CSV File
One problem with our current ExoplanetStore type is that it doesn’t yet contain any data to query. To fix that, we’ll load it with the data of every Exoplanet discovered to date from NASA’s Exoplanet Archive.
There are hundreds of configuration options for this incredible resource, but today we want each exoplanet’s name and its discovery year packaged as a CSV. Checking the docs gives us the following endpoint:
https://exoplanetarchive.ipac.caltech.edu/TAP/sync?query=select+pl_name+,+disc_year+from+pscomppars&format=csv
Once we have our CSV downloaded locally, we can use the following SQL command to load it as a new table within our DuckDB in-memory database. DuckDB’s read_csv_auto command automatically infers our table schema and the data is immediately available for analysis.
CREATE TABLE exoplanets AS
SELECT * FROM read_csv_auto('downloaded_exoplanets.csv');
Let’s package this up as a new asynchronous factory method on our ExoplanetStore type:
import DuckDB
import Foundation
final class ExoplanetStore {
// Factory method to create and prepare a new ExoplanetStore
static func create() async throws -> ExoplanetStore {
// Create our database and connection as described above
let database = try Database(store: .inMemory)
let connection = try database.connect()
// Download the CSV from the exoplanet archive
let (csvFileURL, _) = try await URLSession.shared.download(
from: URL(string: "https://exoplanetarchive.ipac.caltech.edu/TAP/sync?query=select+pl_name+,+disc_year+from+pscomppars&format=csv")!)
// Issue our first query to DuckDB
try connection.execute("""
CREATE TABLE exoplanets AS (
SELECT * FROM read_csv_auto('\(csvFileURL.path)')
);
""")
// Create our pre-populated ExoplanetStore instance
return ExoplanetStore(
database: database,
connection: connection
)
}
// Let's make the initializer we defined previously
// private. This prevents anyone accidentally instantiating
// the store without having pre-loaded our Exoplanet CSV
// into the database
private init(database: Database, connection: Connection) {
// ...
}
}
Querying the Database
Now that the database is populated with data, it’s ready to be analyzed. Let’s create a query which we can use to plot a chart of the number of exoplanets discovered by year.
SELECT disc_year, count(disc_year) AS Count
FROM exoplanets
GROUP BY disc_year
ORDER BY disc_year;
Issuing the query to DuckDB from within Swift is simple. We’ll again make use of an async function from which to issue our query. This means the callee won’t be blocked while the query is executing. We’ll then cast the result columns to Swift native types using DuckDB’s ResultSet cast(to:) family of methods, before finally wrapping them up in a DataFrame from the TabularData framework ready for presentation in the UI.
...
import TabularData
extension ExoplanetStore {
// Retrieves the number of exoplanets discovered by year
func groupedByDiscoveryYear() async throws -> DataFrame {
// Issue the query we described above
let result = try connection.query("""
SELECT disc_year, count(disc_year) AS Count
FROM exoplanets
GROUP BY disc_year
ORDER BY disc_year
""")
// Cast our DuckDB columns to their native Swift
// equivalent types
let discoveryYearColumn = result[0].cast(to: Int.self)
let countColumn = result[1].cast(to: Int.self)
// Use our DuckDB columns to instantiate TabularData
// columns and populate a TabularData DataFrame
return DataFrame(columns: [
TabularData.Column(discoveryYearColumn)
.eraseToAnyColumn(),
TabularData.Column(countColumn)
.eraseToAnyColumn(),
])
}
}
Visualizing the Results
In just a few lines of code, our database has been created, populated and analyzed – all that’s left to do now is present the results.
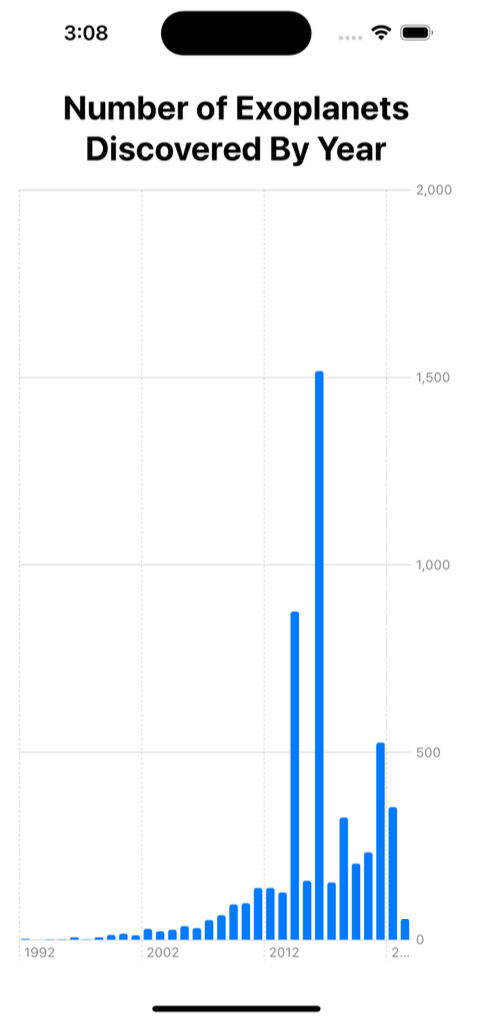
And I have a feeling that we’re just getting started…
For the complete example project – including the SwiftUI views and Chart definitions used to create the screenshot above – clone the DuckDB Swift repo and open up the runnable app project located in Examples/SwiftUI/ExoplanetExplorer.xcodeproj.
We encourage you to modify the code, explore the Exoplanet Archive and DuckDB, and make some discoveries of your own – interplanetary or otherwise!
Conclusion
In this article we’ve introduced the brand new Swift API for DuckDB and demonstrated how quickly you can get up and running analyzing data.
With DuckDB’s incredible performance and analysis capabilities and Swift’s vibrant eco-system and platform support, there’s never been a better time to begin exploring analytical datasets in Swift.
We can’t wait to see what you do with it. Feel free to reach out on our Discord if you have any questions!
The Swift API for DuckDB is packaged using Swift Package Manager and lives in a new top-level repository available at https://github.com/duckdb/duckdb-swift.

