Modern Data Stack in a Box with DuckDB
TL;DR: A fast, free, and open-source Modern Data Stack (MDS) can now be fully deployed on your laptop or to a single machine using the combination of DuckDB, Meltano, dbt, and Apache Superset.

This post is a collaboration with Jacob Matson and cross-posted on dataduel.co.
Summary
There is a large volume of literature, e.g., 1 and 2, about scaling data pipelines. “Use Kafka! Build a lake house! Don't build a lake house, use Snowflake! Don't use Snowflake, use XYZ!” However, with advances in hardware and the rapid maturation of data software, there is a simpler approach. This article will light up the path to highly performant single node analytics with an MDS-in-a-box open source stack: Meltano, DuckDB, dbt, & Apache Superset on Windows using Windows Subsystem for Linux (WSL). There are many options within the MDS, so if you are using another stack to build an MDS-in-a-box, please share it with the community on the DuckDB Twitter, GitHub, or Discord, or the dbt slack! Or just stop by for a friendly debate about our choice of tools!
Motivation
What is the Modern Data Stack, and why use it? The MDS can mean many things (see examples and a historical perspective), but fundamentally it is a return to using SQL for data transformations by combining multiple best-in-class software tools to form a stack. A typical stack would include (at least!) a tool to extract data from sources and load it into a data warehouse, dbt to transform and analyze that data in the warehouse, and a business intelligence tool. The MDS leverages the accessibility of SQL in combination with software development best practices like git to enable analysts to scale their impact across their companies.
Why build a bundled Modern Data Stack on a single machine, rather than on multiple machines and on a data warehouse? There are many advantages!
- Simplify for higher developer productivity
- Reduce costs by removing the data warehouse
- Deploy with ease either locally, on-premise, in the cloud, or all 3
- Eliminate software expenses with a fully free and open-source stack
- Maintain high performance with modern software like DuckDB and increasingly powerful single-node compute instances
- Achieve self-sufficiency by completing an end-to-end proof of concept on your laptop
- Enable development best practices by integrating with GitHub
- Enhance security by (optionally) running entirely locally or on-premise
If you contribute to an open-source community or provide a product within the Modern Data Stack, there is an additional benefit!
- Increase adoption of your tool by providing a free and self-contained example stack
- Dagster's example project uses DuckDB for this already!
- Reach out on the DuckDB Twitter, GitHub, or Discord, or the dbt slack to share an example using your tool with the community!
Trade-offs
One key component of the MDS is the unlimited scalability of compute. How does that align with the MDS-in-a-box approach? Today, cloud computing instances can vertically scale significantly more than in the past (for example, 224 cores and 24 TB of RAM on AWS!). Laptops are more powerful than ever. Now that new OLAP tools like DuckDB can take better advantage of that compute, horizontal scaling is no longer necessary for many analyses! Also, this MDS-in-a-box can be duplicated with ease to as many boxes as needed if partitioned by data subject area. So, while infinite compute is sacrificed, significant scale is still easily achievable.
Due to this tradeoff, this approach is more of an “Open Source Analytics Stack in a box” than a traditional MDS. It sacrifices infinite scale for significant simplification and the other benefits above.
Choosing a Problem
Given that the NBA season is starting soon, a monte carlo type simulation of the season is both topical and well-suited for analytical SQL. This is a particularly great scenario to test the limits of DuckDB because it only requires simple inputs and easily scales out to massive numbers of records. This entire project is held in a GitHub repo, which you can find on GitHub.
Building the Environment
The detailed steps to build the project can be found in the repo, but the high-level steps will be repeated here. As a note, Windows Subsystem for Linux (WSL) was chosen to support Apache Superset, but the other components of this stack can run directly on any operating system. Thankfully, using Linux on Windows has become very straightforward.
- Install Ubuntu 20.04 on WSL.
- Upgrade your packages (
sudo apt update). - Install python.
- Clone the git repo.
- Run
make buildand thenmake runin the terminal. - Create super admin user for Superset in the terminal, then login and configure the database.
- Run test queries in superset to check your work.
Meltano as a Wrapper for Pipeline Plugins
In this example, Meltano pulls together multiple bits and pieces to allow the pipeline to be run with a single statement. The first part is the tap (extractor) which is 'tap-spreadsheets-anywhere'. This tap allows us to get flat data files from various sources. It should be noted that DuckDB can consume directly from flat files (locally and over the network), or SQLite and PostgreSQL databases. However, this tap was chosen to provide a clear example of getting static data into your database that can easily be configured in the meltano.yml file. Meltano also becomes more beneficial as the complexity of your data sources increases.
plugins:
extractors:
- name: tap-spreadsheets-anywhere
variant: ets
pip_url: git+https://github.com/ets/tap-spreadsheets-anywhere.git
# data sources are configured inside of this extractor
The next bit is the target (loader), 'target-duckdb'. This target can take data from any Meltano tap and load it into DuckDB. Part of the beauty of this approach is that you don't have to mess with all the extra complexity that comes with a typical database. DuckDB can be dropped in and is ready to go with zero configuration or ongoing maintenance. Furthermore, because the components and the data are co-located, networking is not a consideration and further reduces complexity.
loaders:
- name: target-duckdb
variant: jwills
pip_url: target-duckdb~=0.4
config:
filepath: /tmp/mdsbox.db
default_target_schema: main
Next is the transformer: 'dbt-duckdb'. dbt enables transformations using a combination of SQL and Jinja templating for approachable SQL-based analytics engineering. The dbt adapter for DuckDB now supports parallel execution across threads, which makes the MDS-in-a-box run even faster. Since the bulk of the work is happening inside of dbt, this portion will be described in detail later in the post.
transformers:
- name: dbt-duckdb
variant: jwills
pip_url: dbt-core~=1.2.0 dbt-duckdb~=1.2.0
config:
path: /tmp/mdsbox.db
Lastly, Apache Superset is included as a Meltano utility to enable some data querying and visualization. Superset leverages DuckDB's SQLAlchemy driver, duckdb_engine, so it can query DuckDB directly as well.
utilities:
- name: superset
variant: apache
pip_url: apache-superset==1.5.0 markupsafe==2.0.1 duckdb-engine==0.6.4
With Superset, the engine needs to be configured to open DuckDB in “read-only” mode. Otherwise, only one query can run at a time (simultaneous queries will cause locks). This also prevents refreshing the Superset dashboard while the pipeline is running. In this case, the pipeline runs in under 8 seconds!
Wrangling the Data
The NBA schedule was downloaded from basketball-reference.com, and the Draft Kings win totals from Sept 27th were used for win totals. The schedule and win totals make up the entirety of the data required as inputs for this project. Once converted into CSV format, they were uploaded to the GitHub project, and the meltano.yml file was updated to reference the file locations.
Loading Sources
Once the data is on the web inside of GitHub, Meltano can pull a copy down into DuckDB. With the command meltano run tap-spreadsheets-anywhere target-duckdb, the data is loaded into DuckDB, and ready for transformation inside of dbt.
Building dbt Models
After the sources are loaded, the data is transformed with dbt. First, the source models are created as well as the scenario generator. Then the random numbers for that simulation run are generated – it should be noted that the random numbers are recorded as a table, not a view, in order to allow subsequent re-runs of the downstream models with the graph operators for troubleshooting purposes (i.e., dbt run -s random_num_gen+). Once the underlying data is laid out, the simulation begins, first by simulating the regular season, then the play-in games, and lastly the playoffs. Since each round of games has a dependency on the previous round, parallelization is limited in this model, which is reflected in the dbt DAG, in this case conveniently hosted on GitHub Pages.
There are a few more design choices worth calling out:
- Simulation tables and summary tables were split into separate models for ease of use / transparency. So each round of the simulation has a sim model and an end model – this allows visibility into the correct parameters (conference, team, elo rating) to be passed into each subsequent round.
- To prevent overly deep queries, 'reg_season_end' and 'playoff_sim_r1' have been materialized as tables. While it is slightly slower on build, the performance gains when querying summary tables (i.e., 'season_summary') are more than worth the slowdown. However, it should be noted that even for only 10k sims, the database takes up about 150 MB in disk space. Running at 100k simulations easily expands it to a few GB.
Connecting Superset
Once the dbt models are built, the data visualization can begin. An admin user must be created in superset in order to log in. The instructions for connecting the database can be found in the GitHub project, as well as a note on how to connect it in 'read only mode'.
There are 2 models designed for analysis, although any number of them can be used. 'season_summary' contains various summary statistics for the season, and 'reg_season_sim' contains all simulated game results. This second data set produces an interesting histogram chart. In order to build data visualizations in superset, the dataset must be defined first, the chart built, and lastly, the chart assigned to a dashboard.
Below is an example Superset dashboard containing several charts based on this data. Superset is able to clearly summarize the data as well as display the level of variability within the monte carlo simulation. The duckdb_engine queries can be refreshed quickly when new simulations are run.
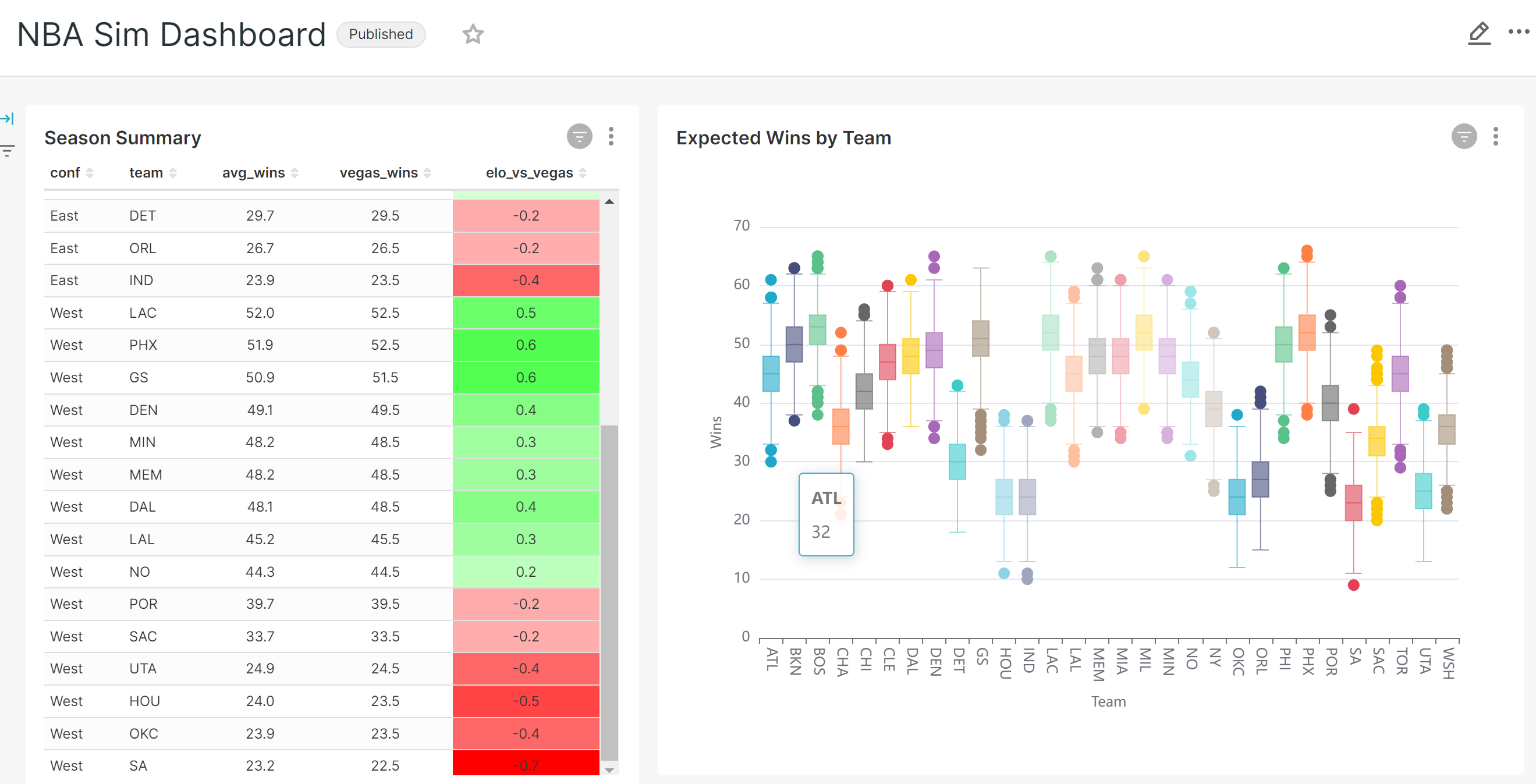
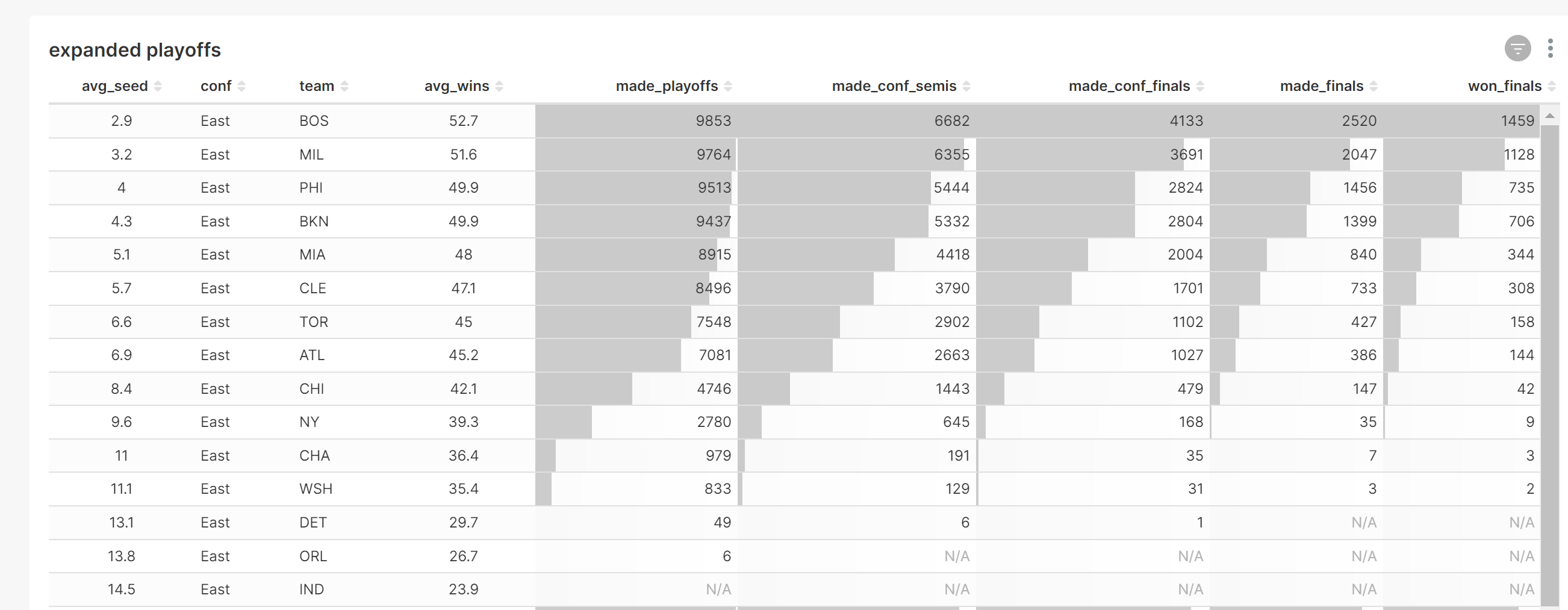
Conclusion
The ecosystem around DuckDB has grown such that it integrates well with the Modern Data Stack. The MDS-in-a-box is a viable approach for smaller data projects, and would work especially well for read-heavy analytics. There were a few other learnings from this experiment. Superset dashboards are easy to construct, but they are not scriptable and must be built in the GUI (the paid hosted version, Preset, does support exporting as YAML). Also, while you can do monte carlo analysis in SQL, it may be easier to do in another language. However, this shows how far you can stretch the capabilities of SQL!
Next Steps
There are additional directions to take this project. One next step could be to Dockerize this workflow for even easier deployments. If you want to put together a Docker example, please reach out! Another adjustment to the approach could be to land the final outputs in parquet files, and to read them with in-memory DuckDB connections. Those files could even be landed in an S3-compatible object store (and still read by DuckDB), although that adds complexity compared with the in-a-box approach! Additional MDS components could also be integrated for data quality monitoring, lineage tracking, etc.
Josh Wills is also in the process of making an interesting enhancement to dbt-duckdb! Using the sqlglot library, dbt-duckdb would be able to automatically transpile dbt models written using the SQL dialect of other databases (including Snowflake and BigQuery) to DuckDB. Imagine if you could test out your queries locally before pushing to production… Join the DuckDB channel of the dbt slack to discuss the possibilities!
Please reach out if you use this or another approach to build an MDS-in-a-box! Also, if you are interested in writing a guest post for the DuckDB blog, please reach out on Discord!

